저는 챗GPT를 믿지 않습니다. 이 녀석 구라를 너무 많이 쳐요. 그것도 아주 잘 칩니다, 그럴 듯하게. 그러나 챗GPT도 파이썬 코드 작성에 있어서 만큼은 진심이라서(영어 다음으로 많이 학습된 언어가 파이썬이라죠), 질문만 잘 던지면(=프롬프트만 잘 작성하면) 제법 잘 작동하는 코드를 내놓습니다. 제가 웹사이트 크롤링하는 코드를 짜달라고 부탁한 적이 몇 차례 있는데, 높은 확률로 잘 작동하더군요.
오늘 포스팅에서는 어떻게 질문을 던져야 챗GPT가 잘 작동하는 웹사이트 크롤러를 작성해주는지 알아보겠습니다. 저는 네이버를 예시로 들었지만, 원리만 이해하면 다른 구조의 웹사이트를 크롤링할 때도 써먹을 수 있습니다.
실습 예시
네이버에서 특정 키워드를 검색했을 때 VIEW 영역에 노출되는 검색결과들의 제목과 본문 일부, 게시물 URL 주소를 크롤링해보겠습니다.
아래 스크린샷처럼 "인테리어 트랜드"라는 키워드를 검색하고 VIEW 영역 검색결과로 노출되는 블로그와 카페 게시물을 크롤링하는 겁니다.

프롬프트 작성법
챗GPT에게 코드 작성을 부탁할 때는 '영어'로 작성하는 게 좋습니다. 그리고 되도록이면 복문이 아닌 단문으로 작성할 때 더 나은 답변을 내놓는 것 같아요. 수행해야 하는 작업을 한 문장 한 문장 또박또박 전달하는 거지요.
그렇게 작성된 아래 프롬프트 템플릿은 네이버 외에 다른 웹사이트를 크롤링할 때도 그대로 써먹을 수 있습니다. { } 중괄호 안에 있는 파라미터 값만 크롤링하고자 하는 웹사이트에 맞게 수정해주시면 돼요.
한글로 기재된 부분은 주석이니까 프롬프트 입력하실 땐 빼주세요.
# 챗GPT에게 주문하려는 과업의 개요를 설명: 어떤 웹사이트에 있는 게시물들의 제목, 본문, URL링크를 크롤링하는 파이썬 코드를 작성하려고 해. 이 웹사이트는 무한 스크롤로 구현되어 있어
## 참고로 step-by-step(차근차근)은 챗GPT 답변의 질을 비약적으로 높이는 마법의 단어!!
I want you to write the python code to crawl the title, description and url of each post on a web page STEP-BY-STEP. This web page has been implemented with an infinite scroll UI.
# 웹사이트의 위치를 설명: 이 웹사이트의 URL은 {크롤링 하려는 웹사이트 주소}야
The page url is "{https://search.naver.com/search.naver?where=view&sm=tab_jum&query=%EC%9D%B8%ED%85%8C%EB%A6%AC%EC%96%B4+%ED%8A%B8%EB%9E%9C%EB%93%9C}".
# 크롤링해야 할 요소(Element)들의 식별방법을 설명: 게시물들은 {ul} 태그 안에 있어
The a set(feed) of the posts is in "{ul}"tag and has class name "{lst_total _list_base}".
# 웹사이트의 구조에 대해 간단하게 설명: 하나의 피드를 크롤링하고 나면 그 다음 피드를 불러오기 위해 스크롤을 내려야 해. 그리고나서 게시물의 제목, 본문, URL을 크롤링하는 작업을 반복해야 해.
{When crawling one feed is finished, scroll down is necessary to load the next feed.
And then Repeat the task of crawling the title, description and url of each post on a feed until there is nothing to crawl}.
# 크롤링해야 할 요소(Element)들의 식별방법을 설명: 각 요소(제목, 본문 등)가 속해 있는 태그와 클래스명은 {이러저러}해.
The title of the post is in "{a}" tag and has class name ''{api_txt_lines total_tit _cross_trigger}".
The description of the post is in "{div}" tag and has class name "{api_txt_lines dsc_txt}".
The url of the post is in "{a}" tag and after "{href}".
# 크롤링한 결과물을 어떤 형식으로 저장할 것인지 설명: Dataframe으로 정리한 후 엑셀 파일로 Export해줘.
At the last, I want to make the crawled titles, descriptions and urls into dataframe and then MS excel file.
만약 네이버 말고 다른 웹사이트를 크롤링하는 코드를 요청하고 싶다면 위의 프롬프트 템플릿에서 { } 중괄호로 표시한 아래 내용만 바꿔주면 됩니다:
- 크롤링하려는 웹사이트 URL 주소
- 해당 웹사이트가 콘텐츠를 표시하는 방식(ex. 무한 스크롤, 페이지네이션 등)
- 크롤링하려는 콘텐츠의 요소(제목, 본문, URL 주소 등)
크롤링해야 할 요소(Element) 찾는 법
그런데 많은 분들이 크롤링할 요소의 식별자를 찾아내는 데 어려움을 겪으시더군요. 네이버의 예시를 활용해 식별자 찾아내는 법도 간단하게 안내해 보겠습니다.
1. 웹사이트 접속 후 F12 키를 눌러 개발자 도구 열기
2. 개발자 도구에서 어피치가 손가락질 하고 있는 아이콘을 클릭한 후 크롤링하고자 하는 요소(ex. 제목)에 마우스 커서 갖다 대기

3. 그러면 개발자 도구에 해당 요소의 마크업이 표시되는데 위의 예시에서는 아래 코드가 그것
<a href="https://cafe.naver.com/usehands/32402?art=ZXh0ZXJuYWwtc2VydmljZS1uYXZlci1zZWFyY2gtY2FmZS1wcg.eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJjYWZlVHlwZSI6IkNBRkVfVVJMIiwiY2FmZVVybCI6InVzZWhhbmRzIiwiYXJ0aWNsZUlkIjozMjQwMiwiaXNzdWVkQXQiOjE2ODI4MzA2MzY0MTJ9.EuRHgjWJAwt0weZHeJoCwdVk4jyA4TBAlZuKc6uTmho" class="api_txt_lines total_tit _cross_trigger" data-cr-gdid="90000004_01322A7300007E9200000000" target="_blank" onclick="return goOtherCR(this, 'a=rvw*t.link&r=1&i=90000004_01322A7300007E9200000000&u='+urlencode(this.href))">상업시설 <mark>인테리어</mark>의 정답 <mark>트렌드</mark>를 담은 공간, 목적에 맞는 공간컨설팅~</a>
4. 위 코드에서 맨 앞에 있는 "a"가 태그명이 되고, "class=" 뒤에 있는 값이 Class Name이 되는 것
5. 이렇게 파악된 요소별 식별값을 챗GPT 프롬프트에 적절히 기재하면 끝
프롬프트 실행 결과: 챗GPT가 작성해준 코드
자, 작성한 프롬프트로 챗GPT에게 파이썬 코드를 주문했습니다.
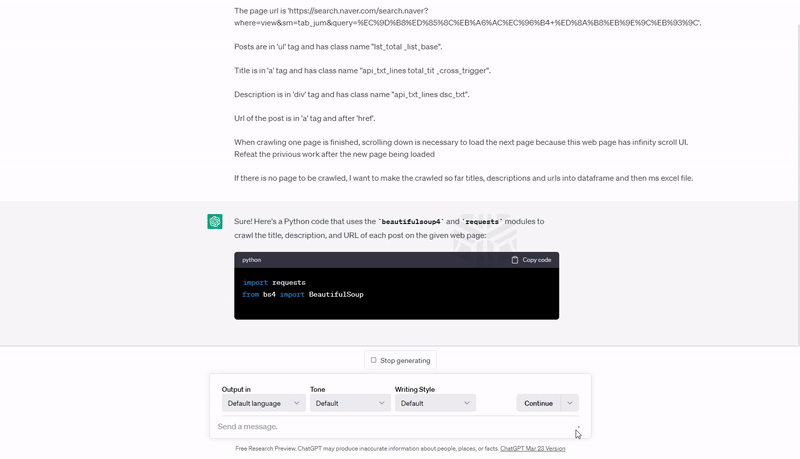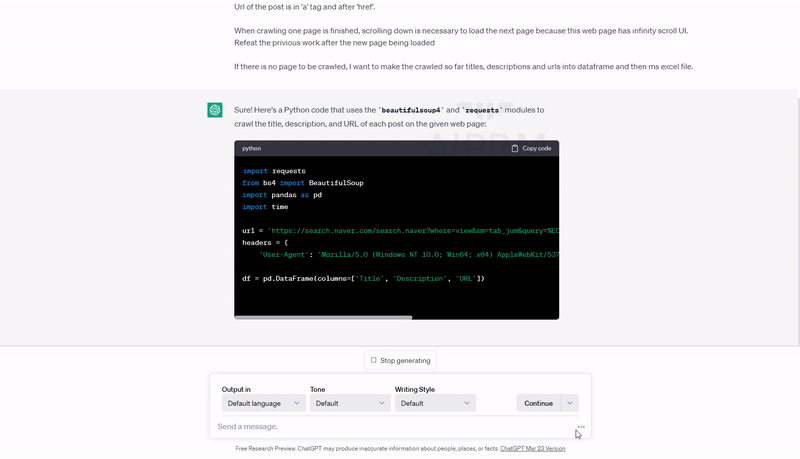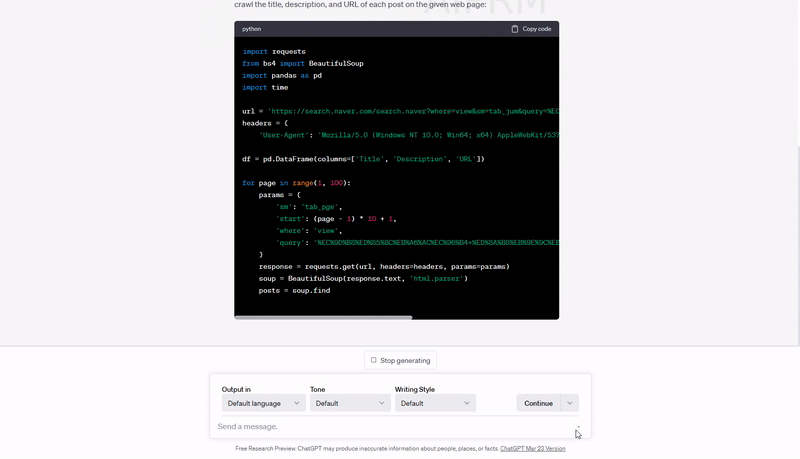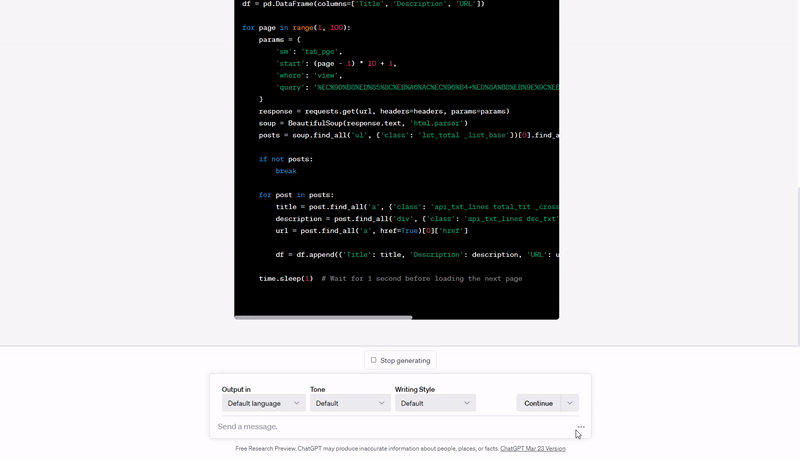
아래는 챗GPT가 내놓은 코드입니다. 중간 for loop 구문의 range 함수 파라미터 값(=scrol down 하는 횟수)만 제가 수정했고요, 다른 부분은 전혀 수정하지 않았습니다.
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import pandas as pd
# set up the webdriver
driver = webdriver.Chrome()
# open the web page
url = 'https://search.naver.com/search.naver?where=view&sm=tab_jum&query=%EC%9D%B8%ED%85%8C%EB%A6%AC%EC%96%B4+%ED%8A%B8%EB%9E%9C%EB%93%9C'
driver.get(url)
# wait for the page to load
time.sleep(3)
# scroll down to load more posts
body = driver.find_element_by_tag_name('body')
for i in range(30):
body.send_keys(Keys.PAGE_DOWN)
time.sleep(1)
# get the posts
posts = driver.find_elements_by_css_selector('ul.lst_total._list_base > li')
# create lists to store the data
titles = []
descriptions = []
urls = []
# loop through each post and extract the title, description, and URL
for post in posts:
title = post.find_element_by_css_selector('a.api_txt_lines.total_tit._cross_trigger').text
description = post.find_element_by_css_selector('div.api_txt_lines.dsc_txt').text
url = post.find_element_by_css_selector('a.api_txt_lines.total_tit._cross_trigger').get_attribute('href')
titles.append(title)
descriptions.append(description)
urls.append(url)
# create a dataframe and export to excel
df = pd.DataFrame({'Title': titles, 'Description': descriptions, 'URL': urls})
df.to_excel('output.xlsx', index=False)
# close the webdriver
driver.quit()
Selenium을 활용해 페이지 스크롤 다운까지 자동으로 수행하며 게시물의 제목과 본문을 크롤링하는, 보기에는 그럴 듯한 코드입니다. 셀레니움 패키지를 활용하기 때문에 크롬 드라이버는 미리 설치가 되어 있어야 정상적으로 작동하겠습니다. 크롬 드라이버 설치 방법은 이 포스팅 맨 아래 링크된 제 예전 게시물을 참고해주세요.
결과물
코드 실행 결과는 ... 대박이네요. 제가 지정한 횟수만큼 스크롤 다운을 수행하고, 로딩된 피드의 게시물들을 따박따박 크롤링해 엑셀 파일로 저장해주었습니다. 아래는 실제 결과 파일 일부입니다.

다만 챗GPT가 동일한 질문에도 매번 다른 답변을 내놓다 보니, 프롬프트를 수정하지 않아도 요청할 때마다 다른 코드를 작성해주네요. 대부분은 제대로 크롤링이 수행되지만 어떤 때는 정상적으로 작동하지 않는 코드를 내줄 때도 있습니다.
노출된 페이지의 제목이나 콘텐츠만 수집하는 거면 거의 실패할 일이 없을 텐데, 무한 스크롤에 대응하여 코드를 작성하는 게 챗GPT에게도 어려운 과업인가 봐요.
크롬 드라이버 설치 방법이 안내된 <인스타 해시태그 검색결과 크롤링>
그렇게 질문할 거면 사용하지 마세요: 챗GPT 프롬프트 작성법 5계명
'Programming > Knowledge' 카테고리의 다른 글
| 영어 회화 공부 유튜브 추천 및 활용 팁 사이트 (0) | 2022.12.26 |
|---|---|
| 데이터 사이언티스트 면접자를 위한 SQL 기본 가이드 (0) | 2022.09.24 |
| 플러터(Flutter)를 학습하는 방법_1 (1) | 2022.08.02 |
| 배우지 말아야 할 6가지 프레임워크와 최선의 대안 (2) | 2022.05.14 |
| [웹 스크래핑] 프리랜서가 추천하는 웹 크롤링 툴 (0) | 2022.02.03 |




댓글