주식투자를 하기 때문에 평소에 증시 캘린더를 즐겨 보는 편입니다. 시중 증권사들 대부분이 나름대로의 형식으로 증시 일정을 정리해 제공하고 있지만, 제가 가장 즐겨 찾아보는 캘린더는 키움 모바일 증시 캘린더입니다. 키움증권에서는 증시 캘린더를 PDF로도 제공하고 있는데 정보가 너무 많아 모바일 가독성이 떨어져서요. 저는 별도로 제공되고 있는 모바일 증시 캘린더를 주로 참고합니다. 아래와 같이 생겼습니다.

이 캘린더는 월중에도 계속 업데이트가 되기 때문에 수시로 들락날락해야 한다는 단점은 있지만요. 보통 직전 월말에 조회를 해보면 다음 달의 '굵직한 이벤트'는 대체로 등재가 되어 있는 상태입니다. 저는 이 시점에 이 캘린더를 크롤링해서 파일로 만든 다음에 제 구글 캘린더에 업로드해둡니다. 일상의 일정을 체크할 때 함께 보일 수 있도록요.
오늘 포스팅에서는 위의 캘린더를 크롤링해 엑셀로 저장까지 하는 코드를 정리해보았습니다.
코딩 전에 준비할 것
이번에 크롤링하려는 증시 일정 사이트는 셀레니움 패키지를 이용해야 합니다. 그러니 미리 아래 절차에 따라 크롬드라이버를 깔아두셔야 합니다. 당연히 크롬 웹브라우저도 설치가 되어 있어야 되겠지요?
Selenium 패키지를 사용하기 위해서는, 크롬드라이버(ChromeDriver)를 다운받아서 앞으로 작성할 파이썬 코드(.py)가 저장될 폴더에 함께 넣어두어야 합니다:
① 먼저 우리 크롬 브라우저의 버전을 확인합니다 :
크롬 브라우저 우상단의 메뉴 > 도움말 > Chrome정보
② 아래 링크된 페이지에서 우리 버전 및 운영체제에 맞는 크롬 웹드라이버를 다운 받습니다:
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 101, please download ChromeDriver 101.0.4951.15 If you are using Chrome version 100, please download ChromeDriver 100.0.4896.60 If you are using Chrome version 99, please download ChromeDriver 99.0.4844.51 F
chromedriver.chromium.org
③ 다운받은 압축파일의 내용물을 코드가 저장된(될) 폴더에 압축 해제합니다.
코딩
본 포스팅은 파이썬에 대한 기본 지식을 갖춘 분들을 위해 작성되었습니다. 때문에 상세한 코드 설명은 생략합니다. 아래의 코드 스니펫(뭉치)들을 순차적으로 실행하시고 나면 엑셀파일이 떡하니 생성되어 있을 거예요.
▼ 코드 설명
수집하려는 사이트의 url을 정의해줍니다. 크롬드라이버느 이 url로 접속해 브라우저를 띄워줄 겁니다. 키움 증시 캘린더의 기본 url 형식은 아래 코드의 url 변수 참고해주세요. url의 date 파라미터에는 수집하고자 하는 월(month)의 아무 날짜나 yyyyMMdd 형식으로 입력하면 됩니다. 저는 4월의 증시 일정을 크롤링할 계획이므로 '20220401'이라고 정의했습니다.
# 필요 패키지 호출
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
import time
import re
import time
import pandas as pd
from lxml import html
from urllib.request import Request, urlopen
from urllib.parse import urlencode, quote_plus, unquote
# 크롤링 하려는 사이트 URL
target_date = "20220401"
url = "https://invest.kiwoom.com/inv/calendar?date={date}".format(date = target_date)
# 크롬 브라우저 열기
driver = webdriver.Chrome('chromedriver.exe')
driver.get(url)
time.sleep(3)
코드 수행결과
위의 코드를 수행하면 크롬이 저절로 열리면서 정의한 url로 이동합니다.
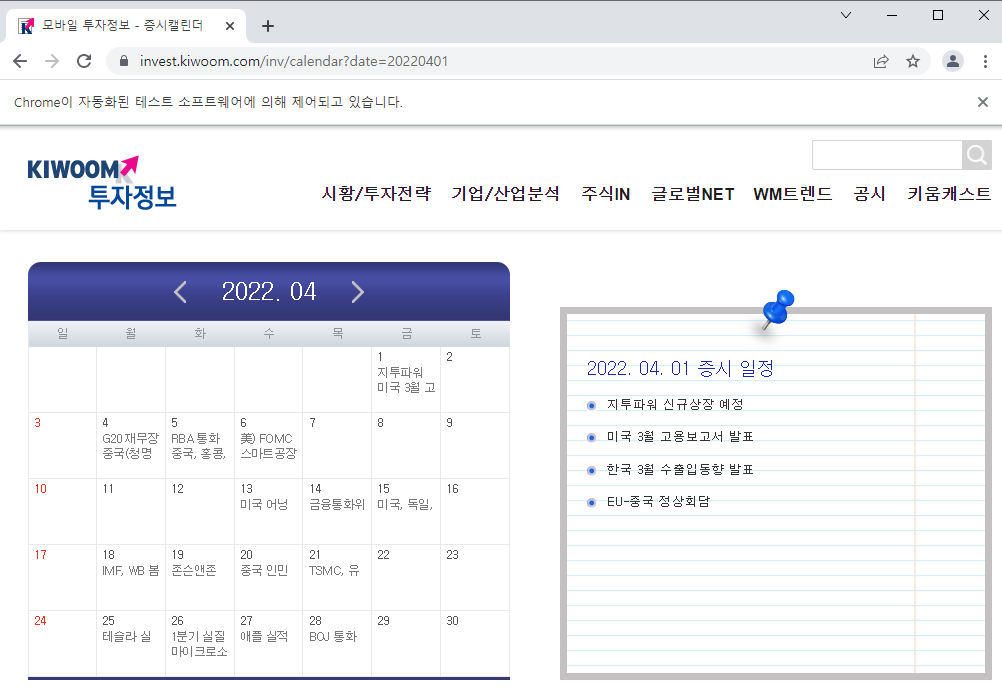
▼ 코드 설명
이 부분의 코드를 작성하려면 미리 크롤링 하려는 사이트의 html 구조를 파악해두어야 합니다. 웹 스크래핑, 웹 크롤링을 주체적으로 해보고 싶다 하시는 분들은 CSS나 HTML에 대한 기본적인 지식을 습득해두시면 좋습니다. 아래 코드는 <li> 태그에 내포된(nested) 콘텐츠 중 class가 'number'인 녀석들을 모두 추출해달라는 뜻입니다.
# 크롤링 하려는 정보가 어떤 <tag>에 nested 되어 있는지 확인 후 findAll
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
rows = soup.findAll("li", {'class': 'number'})
▼ 코드 설명
이제 크롤링한 데이터를 '일자별 이벤트'로 보기 좋게 정리하는 단계입니다. 원본 데이터에는 일(day) 정보만 있고 년도와 월 정보는 없기 때문에 각각 yyyy와 MM 변수로 정의해줍니다. 이 코드 스니펫의 목적은 [일자, 이벤트]를 하나의 요소(element)로 하는 calendar_contet라는 list를 생성하는 것입니다. 처음에는 빈 list를 생성하고, for loop 구문을 통해 요소를 하나하나 채워갑니다. 아래 코드 스니펫 중 이해가 되지 않는 부분이 있다면 댓글 주세요.
# 원본 정보에 년도(year)와 월(month)가 없기 때문에 직접 정의
yyyy = str('2022')
MM = str('04')
# 크롤링한 일자별 이벤트를 일자와 함께 list에 저장
calendar_content = []
for p in range(0, len(rows)):
days = rows[p].find("p", {'class': 'number'}).text.zfill(2) + '/' + MM + '/' + yyyy
events = []
for child in rows[p].find("div", {'class': 'info'}).children:
events.append(str(child))
try:
for i in range(0, len(events)):
calendar_content.append([days, events[i]])
except:
calendar_content.append([days, ""])
▼ 코드 설명
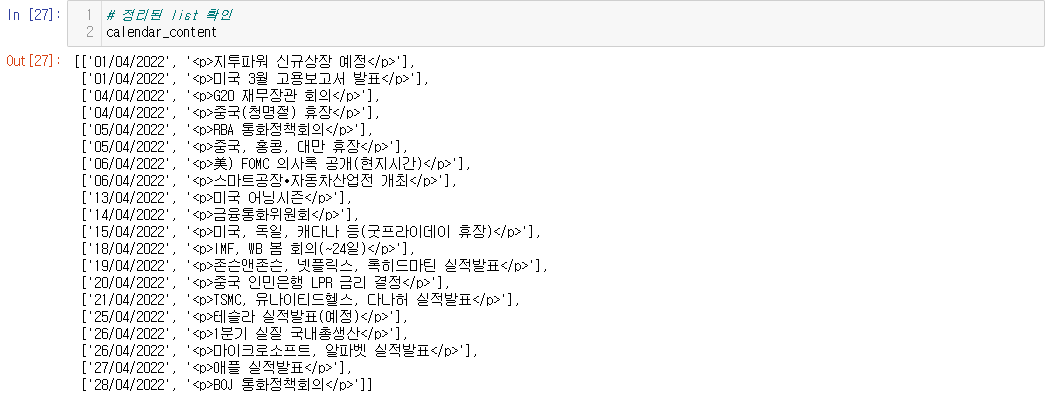
위의 결과로 calendar_contet 리스트의 요소들이 채워졌을 텐데요. 그 결과물을 확인하는 코드입니다.
# 정리된 list 확인
calendar_content
코드 수행결과
[일자, 이벤트]를 한 쌍으로 하는 요소들이 차곡차곡 잘 채워졌네요. 그러나 이벤트에 붙어 있는 <p> 태그가 무척 거슬립니다.
▼ 코드 설명
위의 list를 DataFrame으로 변형하고, 이벤트마다 붙어 있는 <p> 태그를 제거하는 코드 스니펫입니다. 이렇게 전처리된 결과 데이터프레임이 calendar_df이고요, 마지막에 그 결과물을 확인하였습니다.
# list를 판다스 dataframe으로 변형
from pandas import DataFrame
# 컬럼명 지정
calendar_df = DataFrame(calendar_content, columns=[
'Start Date'
, 'Subject'
])
# 이벤트에 붙어 있는 <p> 태그를 제거
calendar_df['Subject'] = calendar_df['Subject'].str.replace('<p>', '')
calendar_df['Subject'] = calendar_df['Subject'].str.replace('</p>', '')
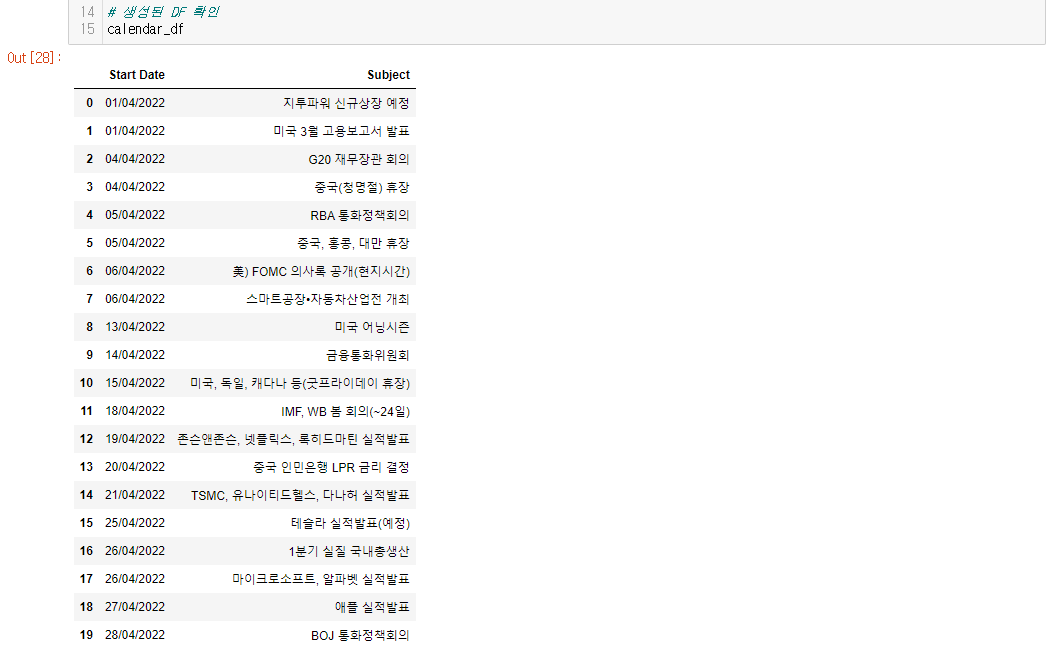
# 생성된 DF 확인
calendar_df
코드 수행결과
의도한 대로 이벤트(Subject 컬럼)의 <p> 태그는 잘 제거되었고, 데이터 형식도 데이터프레임으로 잘 변형됐네요. 아! 일자 형식이 dd/MM/yyyy인 이유는 구글 캘린더에 일정을 연동하기 위함입니다. 구글에서 제공하는 CSV → 캘린더 연동 가이드를 보니 날짜 형식을 dd/MM/yyyy로 요구하고 있더라고요.
▼ 코드 설명
자 다 되었습니다. 위의 데이터프레임을 엑셀 파일로 저장하는 단계입니다.
# 엑셀파일로 저장
from datetime import datetime
calendar_df.to_excel(yyyy+MM+'_market calendar.xlsx', encoding="utf-8", index=False)
이렇게 생성된 엑셀파일을 저는 구글 캘린더에 연동해서 수시로 눈에 띄게 해둔답니다. 엑셀을 통해 구글 캘린더에 일정을 대량으로 업로드하는 방법은 아래 포스팅 참고해주세요:
공모주 상장(IPO), 실적 발표, 각국 증시 휴장일 등 증시 주요 일정 구글 캘린더 연동하기
'Programming > Code Archive' 카테고리의 다른 글
| 미국 주식 재무제표 크롤링으로 배우는 파이썬 Selenium 기초 (0) | 2022.05.08 |
|---|---|
| FOMC 회의 발표 스크립트 확인 방법과 출현 단어 분석 (0) | 2022.05.06 |
| [파이썬Python-API] 금융감독원 오픈 API로 적금상품 스크래핑 (0) | 2022.03.17 |
| [파이썬Python-웹 스크래핑] 구글 플레이 스토어 앱 리뷰 크롤링 (0) | 2022.02.02 |
| [파이썬Python-웹 스크래핑] 채용공고 내 단어 출현빈도 분석하고 시각화 feat.자연어처리 (1) | 2022.01.01 |




댓글