주의!
구글 플레이 스토어 프론트가 최근에 개편 되었더군요. 당연히 마크업 구조도 수정되었고, 본 포스팅의 코드는 무용지물이 되었습니다. 해서 새로 개편된 구조에 맞는 웹 크롤러를 새로 프로그래밍했으니 아래 포스팅 참고해주세요.
[파이썬] 개편된 구글 플레이 스토어! 앱 리뷰 크롤링
하고 있는 업무 때문에 시중 어플리케이션 몇 가지의 리뷰를 크롤링 하려 구글 플레이 스토어를 방문했습니다. 그런데 화면이 개편되어 있더군요. 모골이 송연해졌습니다. 그러면 클로링을 위
mokeya.tistory.com
평소 웹 스크래핑에 관심이 많습니다.
주로 투자에 도움이 될 만한 경제/재무지표를 수집하는 데 사용하고 있지만
가끔은 다른 관심 있는 이슈에 대한 정보를 얻을 때에도
웹 스크래핑 혹은 웹 크롤링을 사용합니다.
최근에는 안드로이드의 앱 마켓인 '구글 플레이 스토어'에서
관심 있는 앱의 리뷰 데이터를 수집하는 크롤러를 만들어봤습니다.
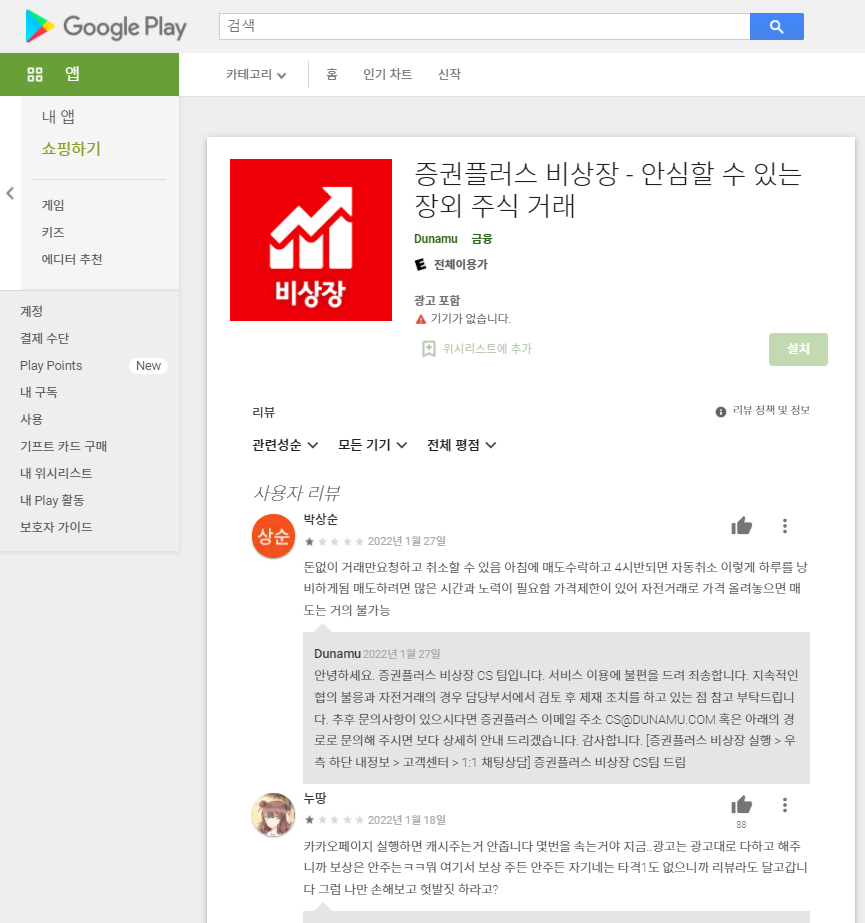
참고로 이 포스팅은 파이썬에 대한 기본 지식이 있는 사람들을 위해 작성했지만,
기본 지식 없이(=코드에 대한 이해 없이) 기계적으로만 따라하셔도
URL만 바꿔 입력하시면 원하는 결과물을 얻는 데는 무리가 없을 겁니다.
만약 크롤링 작업의 핵심 툴인 파이썬 셀레니움(selenium)에 대한 기초를 익히고 싶다면
아래 포스팅을 먼저 읽어보세요.
미국 주식 재무제표 크롤링으로 배우는 파이썬 Selenium 기초
웹 크롤링(혹은 웹 스크래핑)을 하는 여러 가지 방법 중에 파이썬 셀레니움을 활용하는 방식은 난이도가 좀 있는 편입니다. 저 역시 가급적 Selenium 없이 크롤링 하는 걸 선호하지만 어떤 유형의
mokeya.tistory.com
작업환경
1) 파이썬3.7(32bit)
2) 파이썬IDE Anaconda JupyterNotebook
3) 본 크롤러는 크롬 확장프로그램의 도움으로 작동하기 때문에 사전에 크롬이 설치되어 있어야 합니다.
4) 또한 Selenium을 사용하기 때문에, 크롬드라이버(ChromeDriver)를 다운받아서 앞으로 작성할 파이썬 코드(.py)가 저장될 폴더에 함께 넣어두어야 합니다.
① 먼저 우리 크롬 브라우저의 버전을 확인합니다 :
크롬 브라우저 우상단의 메뉴 > 도움말 > Chrome정보(아래 스샷 참고)
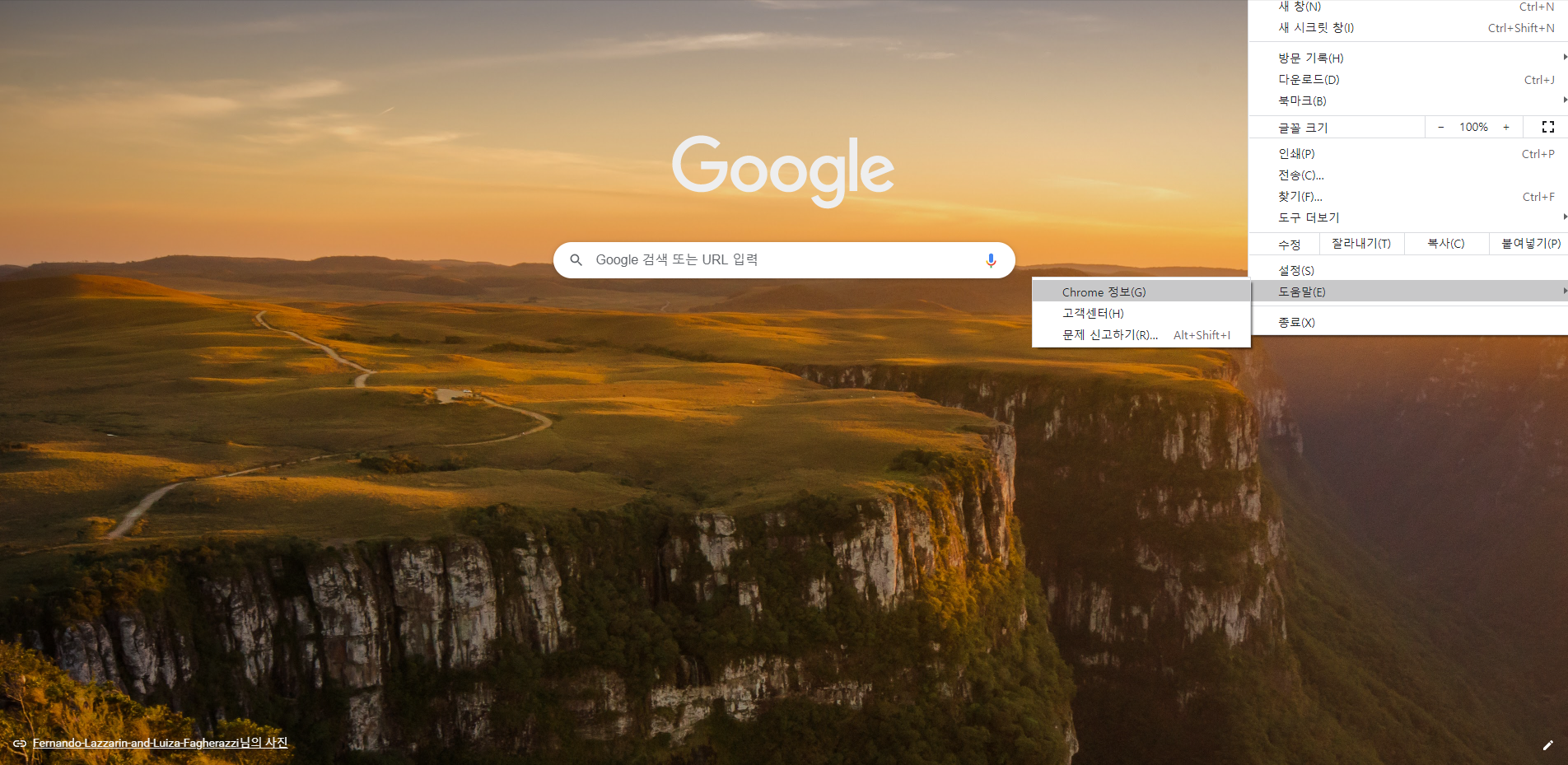
② 아래 링크된 페이지에서 우리 버전 및 운영체제에 맞는 크롬 웹드라이버를 다운 받습니다.
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 98, please download ChromeDriver 98.0.4758.48 If you are using Chrome version 97, please download ChromeDriver 97.0.4692.71 If you are using Chrome version 96, please download ChromeDriver 96.0.4664.45 For o
chromedriver.chromium.org
코드
아래의 코드 스니펫들을 모두 합치면 앱 리뷰 크롤러가 됩니다.
크롤링하고자 하는 리뷰 페이지의 URL을 입력받습니다.
이 때 URL은 "리뷰 모두 보기"를 클릭한 후의 페이지 URL이어야 합니다(아래 스크린샷 참고).
# 크롤링하고자 하는 리뷰 페이지의 url을 적어준다.
url = input('스크래핑할 URL 주소를 입력 :')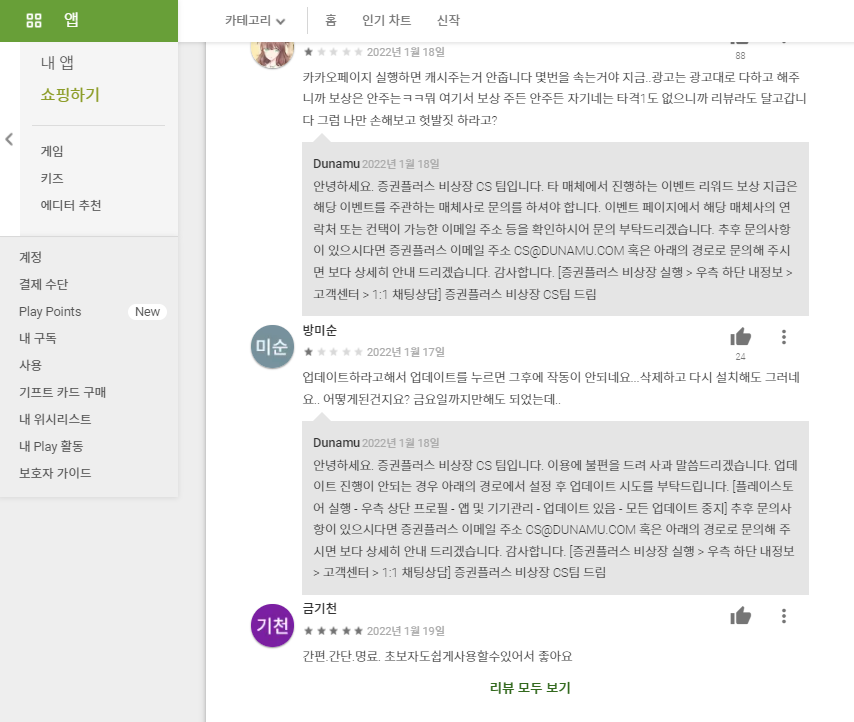
다음으로 "리뷰 모두 보기" 페이지에서
페이지를 끝까지 스크롤 다운해 모든 리뷰 콘텐트가 페이지 내 노출되도록 하는 코드입니다.
'크롬에서 해당 페이지를 열어 스크롤을 끝까지 다운'하는 행위는
우리가 직접 하는 것이 아니라 selenium 패키지가 대신 해줍니다.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.add_argument('--kiosk') # 화면을 전체화면으로 열어주기 위해서
driverPath = "chromedriver.exe" # 크롬드라이버 설치된 경로. 파이썬(.py) 저장 경로와 동일하면 그냥 파일명만
driver = webdriver.Chrome(driverPath, options=options) # Open Chrome
driver.get(url) # 위의 패러그래프에서 입력한 URL
SCROLL_PAUSE_TIME = 2
SCROLL_TIMES = 4 # 4번 스크롤 후 더보기 버튼 생성되기에 4
CLICK_PAUSE_TIME = 2
# 리뷰 페이지의 마지막까지 스크롤 다운하기 위해 페이지의 높이를 return
last_height = driver.execute_script("return document.body.scrollHeight")
# 스크롤 가장 아래까지 내리기 ('더보기' 누르면서)
while True:
for i in range(SCROLL_TIMES):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME) # 스크롤 다운 사이에 2초의 인터벌을 두어 에러를 방지
# 중간중간 '전체 리뷰' 버튼 누르기
spread_review = driver.find_elements_by_xpath("//button[@jsaction='click:TiglPc']")
for i in range(len(spread_review)):
isTrue = spread_review[i].is_displayed()
if isTrue:
driver.execute_script("arguments[0].click()", spread_review[i])
time.sleep(CLICK_PAUSE_TIME)
more_button = driver.find_elements_by_xpath("//span[@class='RveJvd snByac']")
# '전체 리뷰' 버튼이 있다면 눌러준다
if more_button:
more_button[0].click()
# 더이상 내려가는 곳이 없으면 break
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
제가 이 리뷰 페이지에서 수집하고자 하는 요소는
'앱 이름', 사용자의 '리뷰 내용' 그리고 '별점'입니다.
각 수집 요소를 데이터프레임 형식으로 차곡차곡 쌓을 겁니다.
# 수집 대상 요소를 컬럼으로 하는 빈 DF 생성
data = pd.DataFrame(data=[], columns=['앱이름', '리뷰', '별점'])
# 앱 이름
app_name = driver.find_element_by_css_selector('.AHFaub')
# 리뷰 내용
review = driver.find_elements_by_xpath("//span[@jsname='bN97Pc']")
# 별점
score = driver.find_elements_by_xpath('//div[@class="pf5lIe"]/div[@role="img"]')
# for loop 구문 통해 각 요소의 데이터를 수집
for i in range(len(review)):
tmp_df = []
tmp_df.append(app_name.text)
tmp_df.append(review[i].text)
tmp_df.append(score[i].get_attribute('aria-label'))
tmp_df = pd.DataFrame(data=[tmp_df], columns=data.columns)
data = pd.concat([data,tmp_df])
print(app_name.text + "앱 리뷰 수집 완료")
# 인덱스 번호를 다시 0부터 리셋
data.reset_index(inplace=True, drop=True)
data.head()
수집한 데이터프레임을 보니 별점 데이터가
"별표 5개 만점에 N개를 받았습니다."라는 문자열이었네요(아래 스크린샷).
N에 해당하는 숫자만 남기고 나머지는 제거하도록 하겠습니다.

# 원본 데이터 카피
tmp = data.copy()
# 앞의 별표 5점은 생략. 정규 표현식을 사용해 숫자만 추출. "별표 5개"를 생략
tmp['별점'] = tmp['별점'].apply(lambda x: x[5:])
# re 라이브러리를 임포트 후 정규표현식 사용
import re
'''
정수형 숫자 1개만 있거나, 4.8 과 같이 소수점으로 계산된 점수를 추출
[0-9]는 0부터 9까지의 숫자 중 하나를 의미
"\"는 뒤에 오는 "."를 정규표현식이 아니라 있는 그대로의 문자열(".")로서 인식하도록 함
"."은 어떤 문자든 1개가 등장함을 의미
*은 앞의 문자(숫자, 특수문자 포함)가 0개 이상 등장함을 의미
'''
m = re.compile('[0-9][\.0-9]*')
tmp['별점'] = tmp['별점'].apply(lambda x : m.findall(x)[0])
tmp.head(3)
이제 데이터프레임에는 전처리까지 완료된 데이터가 깔금하게 들어가 있습니다.
데이터를 CSV와 XLSX 형식으로 각각 저장하고 마치겠습니다.
# 다양한 형식으로 저장
tmp.to_csv(app_name.text+'_리뷰평점.csv', encoding='utf-8') # CSV로
tmp.to_excel(app_name.text+'_리뷰평점.xlsx') # xlsx로
'Programming > Code Archive' 카테고리의 다른 글
| [파이썬Python-웹스크래핑] 키움증권 증시 일정/캘린더 크롤링 (0) | 2022.04.02 |
|---|---|
| [파이썬Python-API] 금융감독원 오픈 API로 적금상품 스크래핑 (0) | 2022.03.17 |
| [파이썬Python-웹 스크래핑] 채용공고 내 단어 출현빈도 분석하고 시각화 feat.자연어처리 (1) | 2022.01.01 |
| [파이썬Python] 데이터 분석을 빠르고 수월하게 해주는 치트키 5개_2탄 (2) | 2021.09.15 |
| [파이썬Python] 데이터 분석을 빠르고 수월하게 해주는 치트키 5개_1탄 (0) | 2021.09.13 |




댓글