요즘은 일자리를 구하려면, 특히나 내로라는 외국계에 취합하고자 한다면
일단 기업의 지원자선별시스템(ATS, Applicant Tracking System)의 눈에 띄는 것이 중요합니다.
ATS라는 기계적인 용어가 다소 거북할 수 있지만 포춘 500대 기업의 99%가
이미 해당 솔루션을 사용하고 있을 정도로 공공연하게 알려진 도구입니다.
나라는 사람이 그 기업의, 그 직무에 더할나위 없이 딱 맞는 인재라 할지라도
당신의 이력서가 이를 담아내지 못 하면(=ATS의 레이더에 걸리지 못 하면)
결국은 수많은 이름 없는 지원자들 중 한 명으로 남게 될 겁니다.
결국 '알고리즘'이 적합한 구직자를 선별해내는 요즘 시대에
구직자 역시 그 알고리즘을 역이용(like 태극권)할 수 있는
어느 정도의 데이터 리터러시, 혹은 코드 리터러시가 필요하다는 생각이 드는데요.
오늘 공유할 프로그램은 몇 줄 안 되는 코드로 작성되었지만
ATS에 최적화된 이력서를 써내는 데 필요한, 단순하면서도 유용한 정보를 제공해줍니다.
기업의 채용공고에서 어떤 단어가 얼마나 출현하는지 보여주는 프로그램이에요.
1단계 : 필수 라이브러리 설치
먼저 프로그램 코딩에 필요한 필수 라이브러리 몇 개를 설치합니다.
Requests나 BeautifulSoup4는 웹문서(HTML)을 추출하고 가공할 때 늘 사용되는 라이브러리입니다.
제가 기업의 재무정보를 크롤링해 퀀트투자 데이터를 만들 때도 항상 사용하고 있지요.
아무튼 본 프로그램을 위해 설치가 필요한 라이브러리는,
- Requests (HTML을 다운로드 하기 위해)
- BeautifulSoup4 (HTML을 파싱하기 위해)
- Matplotlib (데이터 시각화에 널리 사용되는 라이브러리. 얘도 정말 유명합니다)
- konlpy (한글 자연어 처리를 위해)
- nltk (영어 자연어 처리를 위해)
아마 KONLPY를 사용 가능한 상태로 세팅하는 작업이 호락호락하지 않을 텐데요.
(저도 KONLPY 설치에만 3일을 썼네요)
운 좋게 단번에 설치되신 분들 축하드리고요,
아닌 분들은 구글링 좀 해보셔야 할 겁니다, 화이팅.
2단계 : 모듈 Import
필요한 모듈을 불러옵니다.
여기에는 파이썬 표준 라이브러리(라 별도 설치가 필요치 않은)인 Counter 클래스도 포함됩니다.
# Import Modules from collections
import Counter
import requests from bs4
import BeautifulSoup
import matplotlib.pyplot as plt
try:
import jpype
import jpype1
except:
import jpype
from konlpy.tag import Komoran
from konlpy.tag import Okt
from konlpy.utils import pprint
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')모듈 임포트 코드뭉치(snippet)가 위처럼 지저분한 것도 처음인데,
이게 다 konlpy 라이브러리의 지랄맞음과 연관이 있습니다...
3단계 : 웹 스크래핑(HTML 다운로드)
이제 코드 작성할 준비는 끝났습니다.
우리 프로그램은 먼저 스크래핑할 URL을 입력(input) 받는 동작부터 수행하게 될 겁니다.
입력 받아서 HTML을 다운로드까지 하는 게 아래 세 줄 코드로 구현됩니다.
url = input('스크래핑할 URL 주소를 입력 :')
page = requests.get(url)
html = page.text코드 실행 결과

4단계 : HTML에서 원하는 정보만을 추출
다운로드 받은 HTML은 BeautifulSoup를 활용해
필요한 정보만을 추출하는 과정을 거칩니다.
HTML과 CSS에 대한 사전지식이 있다면 이 과정을 훨씬 이해하기 쉽지만
지식이 없더라도 직관적으로 이해할 수 있습니다.
파싱하려는 사이트(LinkedIn)로 가서 개발자 도구(F12)를 여시고요,
마우스 커서를 이리저리 옮겨가면서 추출하고자 하는 요소와, 관련된 태그를 탐색해보세요.
이 포스팅의 주제가 주제인 만큼, 저는 직무명과 회사, 그리고 직무에 대한 설명(JD)만을 가져올 겁니다.
프로그램의 목적이나 여러분이 원하는 바에 따라서 이 부분의 코드를 변경하면
저와는 판이한 결과물을 내놓는 프로그램을 만들 수 있습니다.
soup = BeautifulSoup(html, 'html.parser')
title = soup.find('h1').string
company = soup.find('a', class_ = 'topcard__org-name-link topcard__flavor--black-link').string.replace("\\n", "").strip()
content = soup.find('div', class_ ='show-more-less-html__markup show-more-less-html__markup--clamp-after-5')
body_string = ''
for x in iter(content.stripped_strings):
body_string = body_string + x.lower() body_string추출된 soup 객체들(title, company, content)에는 후처리를 용이하게 하기 위한
string, replace, strip 등의 메서드를 적용했습니다.
string은 객체의 형변환을 위해, replace는 줄바꿈(\\n)을 제거하기 위해, strip은 공백을 제거하기 위해서요.
그리고 for loop 구문에서는 stripped_strings 메서드를 통해
필요치 않은 나머지 HTML(의 아이템)은 제거하였습니다.
코드 실행 결과

5단계 : 자연어 처리
한글 자연어 처리에서 발군의 성능을 발휘하는 KONLPY 라이브러리를 사용해봤습니다.
어떻게 작동하는지는 저도 자세히 알지는 못 하지만
의도한 대로 데이터를 꽤 잘 내놓습니다.
이번 포스팅처럼 채용공고문을 대상으로 하는 분석에서
형용사, 동사, 부사, 조사 같은 형태소는 관심 대상이 아니기 때문에
우리가 찾아낸 공고문에서 명사만을 발췌해 분석해보겠습니다.
그리고 영어든, 한글이든 1개의 음절로만 이루어진 단어는
의미가 없다고 보고, 적어도 2음절 이상의 단어만 리스트(all_nouns)에 포함되도록 했습니다.
# 한국어 형태소 분석 및 명사 추출 함수 정의
okt = Okt()
def tokenize_kor(corpus):
return [word for word in okt.nouns(corpus) if len(word) >=2]
# 영어 형태소 분석 및 명사 추출 함수 정의
def tokenize_eng(corpus) :
is_noun = lambda pos: pos[:2] == "NN"
tokenized = nltk.word_tokenize(corpus)
return [word for (word, pos) in nltk.pos_tag(tokenized) if is_noun(pos) if len(word) >=2]
# 추출된 명사 리스트들 합치기
all_nouns = tokenize_kor(body_string) + tokenize_eng(body_string)
# all_nouns
# 명사별 출현빈도 세기
count = Counter(all_nouns)
# 가장 많이 출현하는 30개
noun_list = count.most_common(30)
for v in noun_list:
print(v)명사들의 리스트(all_nouns)에 Counter 클래스를 적용하면 결과물에는
각 단어와 그 출현빈도를 요소로 하는 튜플로 구성된 리스트가 반환됩니다.
저는 이 중에서 출현빈도가 가장 높은 순으로 상위 30개를 취했습니다.
코드 실행 결과

6단계 : 데이터 시각화
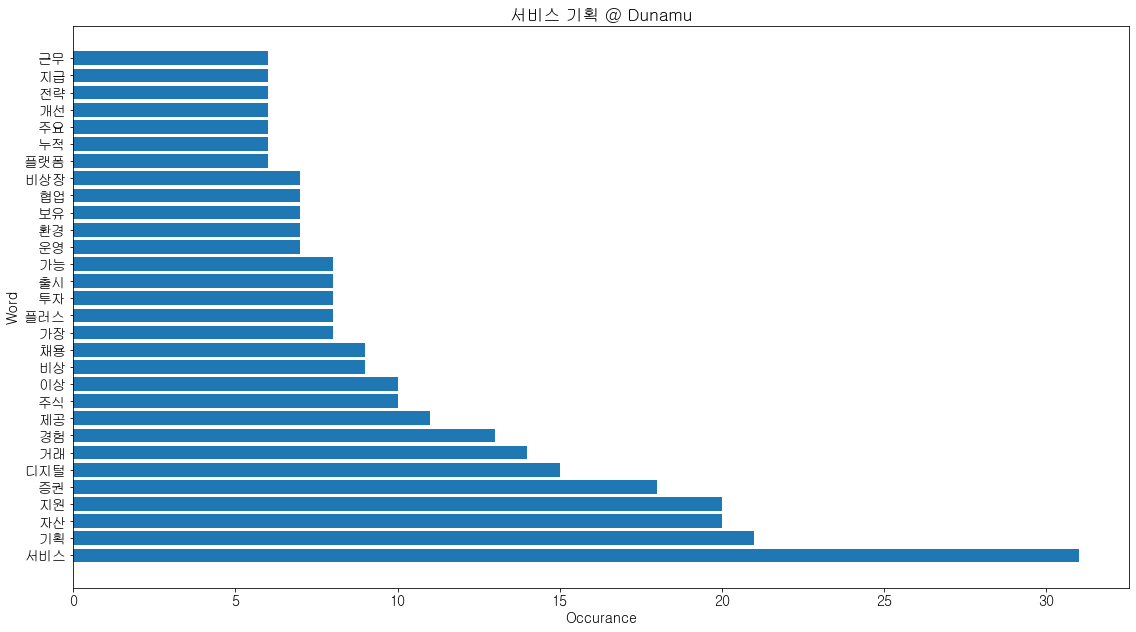
결과물을 가지고 차트를 그렸습니다.
Counter 클래스는 튜플로 구성된 리스트를 반환하기 때문에
키워드와 출현빈도를 각각 X축, Y축으로 활용할 수 있도록 분해해야 합니다.
그 작업은 zip함수로 간단하게 구현했습니다.
# 한글 폰트 사용을 위해서 세팅
from matplotlib import font_manager, rc
font_path = "C:/Windows/Fonts/NGULIM.TTF"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
plt.rcParams["font.size"] = 14
noun, noun_occurance = zip(*noun_list)
plt.figure(0) # Specify differnt figures
plt.figure(figsize=(16,9))
plt.barh(noun, noun_occurance)
plt.title(f'{title} @ {company}')
plt.ylabel('Word')
plt.xlabel('Occurance')
plt.tight_layout() # add padding
plt.savefig(f'{title}.png')코드 실행 결과
7단계 : 본격적으로 활용
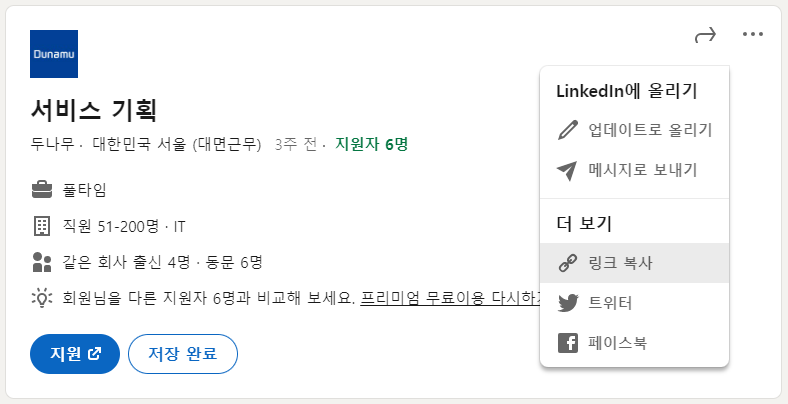
LinkedIn으로 바로 달려가셔서 원하는 공고를 들어가세요.
그리고 아래 화면처럼 더 보기 > 링크 복사를 클릭한 후 그 URL을 방금 만든 프로그램에 입력하세요.
'Programming > Code Archive' 카테고리의 다른 글
| [파이썬Python-API] 금융감독원 오픈 API로 적금상품 스크래핑 (0) | 2022.03.17 |
|---|---|
| [파이썬Python-웹 스크래핑] 구글 플레이 스토어 앱 리뷰 크롤링 (0) | 2022.02.02 |
| [파이썬Python] 데이터 분석을 빠르고 수월하게 해주는 치트키 5개_2탄 (2) | 2021.09.15 |
| [파이썬Python] 데이터 분석을 빠르고 수월하게 해주는 치트키 5개_1탄 (0) | 2021.09.13 |
| [파이썬Python] 코딩 속도를 높여줄 필수 코드(code snippet) 20개 (3) | 2021.09.11 |




댓글