미국 연방준비위원회의 FOMC 회의가 있는 날이면 연준 의장인 파월의 입에 세계의 이목이 집중되곤 합니다. 미국 기준금리 등 우리 투자 성적에 영향을 줄 만한 굵직굵직한 통화정책들이 그 입에서 거론되기 때문이지요. FOMC가 끝나면 연준 의장이 곧바로 컨퍼런스 콜을 하는데 이 때 의장의 발언을 속기한 스크립트가 FOMC 사이트에 곧바로 올라옵니다. 이 실시간에 가깝게 올라오는 FOMC 발표내용을 확보하고 발표에서 주로 언급된 단어들을 분석하는 스킬을 공유합니다.

FOMC 회의 관련 자료 아카이브
https://www.federalreserve.gov/monetarypolicy/fomccalendars.htm
The Fed - Meeting calendars and information
Please enable JavaScript if it is disabled in your browser or access the information through the links provided below. Meeting calendars, statements, and minutes (2017-2022) The FOMC holds eight regularly scheduled meetings during the year and other meetin
www.federalreserve.gov
위의 FOMC 사이트에서 올해 있을 FOMC 회의 일정과 이미 치뤄진 회의 관련 각종 자료(컨퍼런스 콜 발표 스크립트, 정책 실행안, 회의록 등)들이 아카이빙 되어 있습니다. 그 중 컨퍼런스 콜 발표 스크립트는 'Press Conference' 메뉴(아래 스크린샷 참고)에 진입하면 PDF로 확보할 수 있습니다.
발표에서 자주 출현한 단어 분석
01 필요 모듈 설치 및 불러오기
▼ PDF 내 텍스트를 읽어오는 pdfminer 라이브러리를 설치합니다. pdf 읽어오는 여러 라이브러리가 있지만 pdfminer가 성능이 가장 준수한 것 같더라고요.
pip install pdfminer.six
▼ 방금 설치한 pdfminer를 비롯해서 자연어 처리를 위한 여러 가지 라이브러리를 불러옵니다. pdfminer를 비롯해 낯선 라이브러리들 투성이일 텐데, 간단히 설명하자면:
- Requests (HTML을 다운로드 하기 위해)
- BeautifulSoup4 (HTML을 파싱하기 위해)
- Matplotlib (데이터 시각화에 널리 사용되는 라이브러리. 얘도 정말 유명합니다)
- konlpy (한글 자연어 처리를 위해)
- nltk (영어 자연어 처리를 위해)
아마 KONLPY를 사용 가능한 상태로 세팅하는 작업이 호락호락하지 않을 텐데요. 열심히 한 번 찾아보셔야 할 겁니다.
import pdfminer
from pdfminer.high_level import extract_text
import re
import tweepy
print(tweepy.__version__)
from collections import Counter
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
try:
import jpype
import jpype1
except:
import jpype
from konlpy.tag import Komoran
from konlpy.tag import Okt
from konlpy.utils import pprint
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
02 PDF 스크립트 불러오기
▼ FOMC 사이트에서 스크립트(pdf)를 다운받으면 아래와 같은 파일명을 가지고 있습니다. pdf를 불러와 내용을 문자열로 변환합니다.
file_nm = 'FOMCpresconf20220504'
file = f'{file_nm}.pdf'
corpus = extract_text(file)
print(corpus)
03 자연어 처리
▼ 문자열로 변환된 결과물을 보면 May, PRELIMINARY, Chair, Powell, Press, Conference 등 대문자로 구성된, 혹은 대문자로 시작하는 단어들이 빈번히 등장하는 것을 알 수 있습니다. (물론 문장의 첫 단어도 모두 대문자로 시작하겠지요) 특히 Chair, Powell, Press, Conference 같은 단어는 매 페이지마다 머릿말로 찍혀 있기 때문에 출현 빈도로만 보면 그 어떤 단어보다도 자주 출몰합니다. 이런 문자들은 출현은 자주 하지만 큰 의미는 없기 때문에 제거하기로 결정했습니다. 이 결정을 내리기 전에 원본 파일 가지고 출현 빈도를 탐색적으로 분석해봤었는데요, 자주 출현한 대문자를 포함한 문자들 중에 통화정책 해석에 참고할 만한 중요 단어는 없었던 것으로 확인이 되었습니다.
rfnd_corpus = re.sub(r'([A-Z][a-z]+|[A-Z]+)', '', corpus) # Upper case 단어 삭제
print(rfnd_corpus)
▼ 이렇게 대문자 포함 단어를 제거한, 전처리된 코푸스를 가지고 단어별 출현빈도를 분석한 코드 스니펫입니다. 최종 결과물은 단어와 그 출현빈도로 구성된 튜플(tuple)을 요소로 하는 리스트(list) 타입 데이터입니다. 출현빈도 내림차순으로 상위 30개의 단어만 출력했습니다.
# 한국어 형태소 분석 및 명사 추출 함수 정의
okt = Okt()
def tokenize_kor(rfnd_corpus):
return [word for word in okt.nouns(rfnd_corpus) if len(word) >=2]
# 영어 형태소 분석 및 명사 추출 함수 정의
def tokenize_eng(rfnd_corpus) :
is_noun = lambda pos: pos[:2] == "NN"
tokenized = nltk.word_tokenize(rfnd_corpus)
return [word for (word, pos) in nltk.pos_tag(tokenized) if is_noun(pos) if len(word) >=2]
# 추출된 명사 리스트들 합치기
all_nouns = tokenize_eng(rfnd_corpus)
# all_nouns
# 명사별 출현빈도 세기
count = Counter(all_nouns)
# 명사 빈도 카운트
noun_list = count.most_common(30)
for v in noun_list:
print(v)
03 시각화
▼ 정리한 결과물을 가지고 보기 좋게 시각화를 해보겠습니다. 사용한 시각화 라이브러리는 그 유명한 matplotlib입니다.
# 한글 폰트 사용을 위해서 세팅
from matplotlib import font_manager, rc
font_path = "C:/Windows/Fonts/NGULIM.TTF"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
plt.rcParams["font.size"] = 14
noun, noun_occurance = zip(*noun_list)
plt.figure(0) # Specify differnt figures
plt.figure(figsize=(16,9))
plt.barh(noun, noun_occurance)
plt.title(f'{file_nm}')
plt.ylabel('Word')
plt.xlabel('Occurance')
plt.tight_layout() # add padding
plt.savefig(f'{file_nm}.png')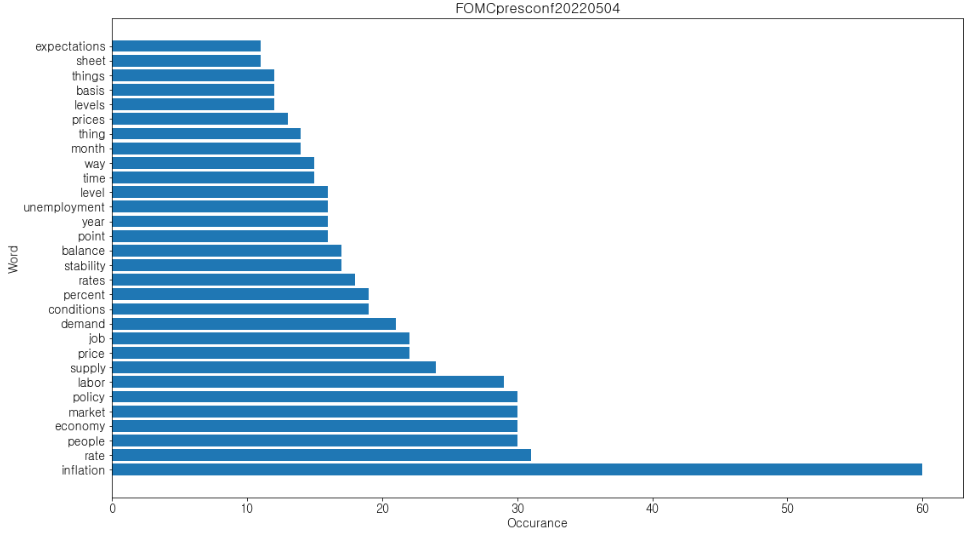
금번 FOMC 후속 기사 내용과 무관하게 이번 분석 결과만 가지고 FOMC에서 중요하게 거론된 화두, 지표 등을 짐작해본다면, 일단 첫 번째 화두는 인플레이션입니다. 더 이상의 설명은 생략합니다. 그리고 labor, supply, job 등의 단어가 그 뒤를 잇고 있습니다. 금번 통화정책 결정에서 고용 지표가 중요한 역할을 했다는 것을 짐작할 수 있습니다. 그러므로 금리 인상의 향방을 가늠하기 위해서라도 고용 지표를 주시할 필요가 있겠습니다.
추출 단어의 수를 30개 이상으로 확장한다면 안 보이던 키워드가 보일 수도 있으니 참고하세요. 또 저는 FOMC의 결론에 대해 가장 먼저 확보할 수 있는 자료가 컨퍼런스 콜 스크립트라 이걸 사용했지만, 시차를 두고 발표되는 회의록을 가지고도 똑같이 단어 출현 빈도를 분석해볼 수도 있습니다.
'Programming > Code Archive' 카테고리의 다른 글
| 파이썬 Tesseract로 OCR(광학식 문자 판독기) 구현하기 (2) | 2022.05.08 |
|---|---|
| 미국 주식 재무제표 크롤링으로 배우는 파이썬 Selenium 기초 (0) | 2022.05.08 |
| [파이썬Python-웹스크래핑] 키움증권 증시 일정/캘린더 크롤링 (0) | 2022.04.02 |
| [파이썬Python-API] 금융감독원 오픈 API로 적금상품 스크래핑 (0) | 2022.03.17 |
| [파이썬Python-웹 스크래핑] 구글 플레이 스토어 앱 리뷰 크롤링 (0) | 2022.02.02 |




댓글