실시간 급상승 검색어를 정해진 시간마다 크롤링해 텔레그램 메시지로 보내주는 봇을 제작합니다. (흰색 말풍선이 봇이 보낸 거고 녹색 말풍선은 접니다)

이 프로젝트는 아래 과업으로 이루어집니다:
텔레그램 봇 API 접근 권한 얻기
실시간 급상승 검색어 크롤링해 텍스트 파일로 저장(현재 글)
웹크롤링과 메시지 발송을 수행하는 텔레그램 봇 만들기
이번 포스팅에서는 실시간 급상승 검색어를 크롤링해 txt 파일로 저장하는 것까지 다룹니다.
준비과정
크롤링하려는 실시간급상승검색어 페이지가 동적으로 구현되어 있기 때문에 HTML을 열어봐도 실급검 정보는 안 보입니다. 그렇기 때문에 BeautifulSoup4 패키지는 사용할 수 없고요. Selenium 패키지를 사용합니다.
Selenium 패키지를 사용한다는 것은 크롬드라이버를 설치해야 된다는 말이고, 그 방법은 이전 포스팅 참고해주세요.
웹 스크래핑(크롤링)을 위한 Selenium 패키지 사용법
작업환경
1) 파이썬3.9(64bit)
2) 파이썬IDE : Pycharm
코드
▼ Selenium 패키지와 크롬드라이브가 설치되었다 가정하고 진행합니다. 필요한 패키지를 불러옵니다.
from selenium import webdriver
from selenium.webdriver.common.by import By
▼ 이제 크롬 드라이버를 통해 실급검 페이지에 접근하는 코드를 짜봅시다. URL 변수에 접근하고자 하는 페이지의 url 주소를 입력하면 파이썬이 크롬 브라우저를 통해 해당 페이지를 띄웁니다.
# Set up the Chrome driver
driver = webdriver.Chrome()
# Navigate to the webpage
URL = "https://signal.bz/" # 스크래핑 하려는 실급검 페이지
driver.get(url=URL)
▼ 바로 이렇게.
스크래핑할 데이터는 <시그널 실시간 검색어> 영역의 기준일시와 10개의 실시간 검색어입니다.

▼ 다음부터는 좀 어렵습니다. 일단 개발자도구(키보드 F12를 누르면 나오는 화면)를 열어서 크롤링할 요소들의 CSS_SELECTOR를 알아내야 합니다. (이 포스팅 서론에 링크한 <Selenium 패키지 사용법> 글을 읽으면 대강의 원리를 이해하실 수 있을 거예요)
일단 아래 스크린샷처럼 요소별로 CSS_SELECTOR 값을 찾아낸 후 코드에 반영하면 됩니다.
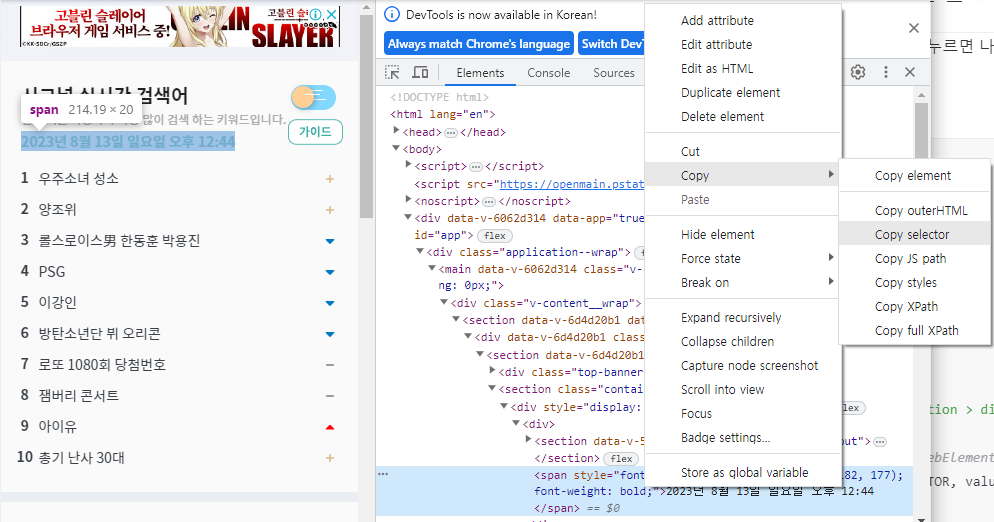
# 실시간 검색어의 '기준일시' 스크래핑
crawling_date = driver.find_element(by=By.CSS_SELECTOR
, value='#app > div > main > div > section > div > section > section:nth-child(2) > div:nth-child(1) > div:nth-child(1) > span').text
# 데이터를 저장할 list 생성
data = [crawling_date, '']
# 10개의 실시간 키워드를 순차적으로 스크래핑
for j in [x for x in range(1, 3)]:
for i in [x for x in range(1, 11)]:
CSS_SELECTOR = f"#app > div > main > div > section > div > section > section:nth-child(2) > div:nth-child(2) > div > div:nth-child({j}) > div:nth-child({i}) > a > span.rank-text"
# Use find_elements to get a list of WebElements
results = driver.find_elements(by=By.CSS_SELECTOR, value=CSS_SELECTOR)
# 스크래핑한 키워드를 만들어둔 list에 순차적으로 저장
for result in results:
print(result.text)
data.append(result.text)
# 드라이버로 띄운 브라우저 닫기
driver.quit()
▲ 10개의 실시간 키워드는 CSS SELECTOR가 모두 다르더군요. 하지만 어떤 규칙성이 있어서 그걸 토대로 for loop 구문으로 코드 작성했습니다.
위의 코드를 실행하면 아래와 같은 list(리스트) 결과를 얻게 됩니다:
data = ['2023년 8월 13일 일요일 오후 12:47', '', '우주소녀 성소', '양조위', '롤스로이스男 한동훈 박용진', 'PSG', '이강인', '방탄소년단 뷔 오리콘', '로또 1080회 당첨번호', '잼버리 콘서트', '아이유', '총기 난사 30대']
▼ 마지막 코드는 list 형태로 저장된 결과를 텍스트 파일로 저장하는 코드입니다.
list의 값 하나하나가 텍스트 파일에서 한줄한줄을 차지하도록 코드를 작성했습니다. 실제 텔레그램 봇이 발송하는 메시지는 이 텍스트 파일의 형식과 동일할 겁니다.
with open('realtime_keywords.txt', 'w') as f:
# list의 값 하나하나가 한 줄을 차지하도록
for item in data:
f.write(item + '\n')
코드 실행 결과 아래와 같이 텍스트 파일이 생성되고,
이걸 열어보면 결과값이 잘 정리되어 있습니다.

바로 복붙해서 채팅창으로 보내도 될 정도의 깔끔한 형식이지요.
-
다음 포스팅에서는 이 메시지를 텔레그램 봇이 발송하도록 하는 작업을 설명하겠습니다.
'Programming > Code Archive' 카테고리의 다른 글
| [파이썬] 실시간급상승검색어 자동 발송하는 봇 만들기 3: 웹크롤링과 메시지 발송을 수행하는 텔레그램 봇 (0) | 2023.08.13 |
|---|---|
| [파이썬] 실시간급상승검색어 자동 발송하는 봇 만들기 1: 텔레그램 봇 생성 (0) | 2023.08.13 |
| [파이썬] 인스타그램 해쉬태그(#) 검색결과 크롤링하기_최신ver. (19) | 2022.08.13 |
| [파이썬-오픈API] 한국은행 경제통계지표 추출 (0) | 2022.07.02 |
| [파이썬] 개편된 구글 플레이 스토어! 앱 리뷰 크롤링 (14) | 2022.06.21 |




댓글