데이터 소개
실제로 한국은행에는 돈다발이 쌓여있다는 점에서 노다지(종의의 집?)이기도 하지만, 투자 의사결정에 도움되는 방대한 데이터들을 보유하고 있다는 점에서 노다지이기도 합니다.
이 데이터들은 모두 오픈API로 공개되어 있기 때문에 파이썬에 대한 이해가 조금만 있으면 내가 관심 있는 통계지표, 거의 모든 경제지표의 긴~ 시계열 데이터를 추출해낼 수 있습니다. 제가 관심을 가지고 있는 지표가 하나 있어 그거 소개 겸, 추출 코드 기록 겸 글을 씁니다.
<뉴스심리지수>라는 지표인데요. 해당 지표가 주가와 무척 높은 상관관계가 있다는 점은 이전 포스팅에서 설명한 바 있습니다.
주가와 경기를 예측하기 위한 선행지표
근미래의 적정 KOSPI 지수를 예측하기 위한 모델을 개발하고 있습니다. 모델에 투입될 피쳐(feature)들은 미래의 코스피와 상관관계가 높은 지표들이 되어야 할 텐데요. '경기가 좋아진다 → 주가가
mokeya.tistory.com
다시 한 번 언급하자면 이 지표는 아래 차트에서처럼 KOSPI와 무척 유사한 움직임(=상관관계가 높음)을 보이고, 어떤 때는 가까운 미래의 KOSPI에 선행하는 듯한 움직임도 보입니다.
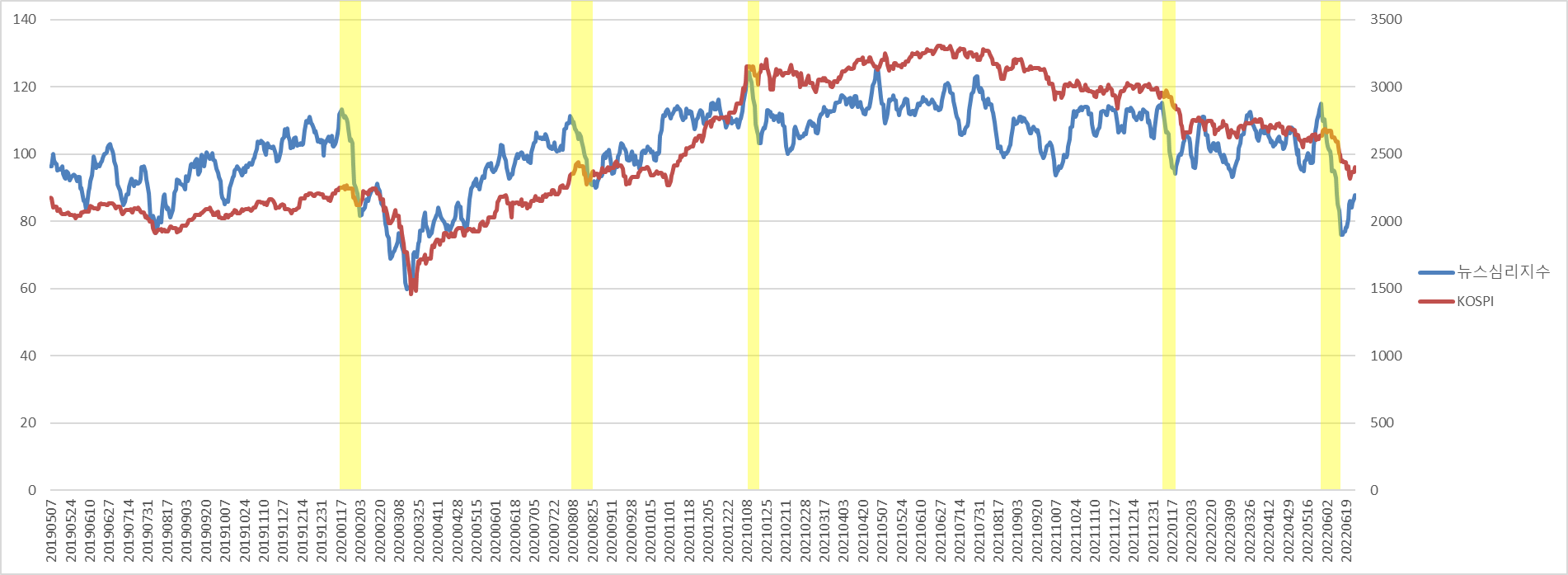
이 지표가 좋은 것은 한국은행에서 매주 화요일에 직전 7일 동안의 지표를 일단위로 정리해 제공한다는 겁니다. 최신의 데이터를 짧은 주기로 제공할수록 의사결정에서의 효용은 높아지지요.
코딩의 결과
추출 코드를 수행하면 아래와 같은 형태의 데이터를 엑셀 파일로 얻게 됩니다:
| 통계명 | 통계항목1코드 | 통계항목명1 | 시점 | 뉴스심리지수 |
| 6.4. 뉴스심리지수(실험적 통계) | A001 | 뉴스심리지수 | 20190501 | 101.26 |
| 6.4. 뉴스심리지수(실험적 통계) | A001 | 뉴스심리지수 | 20190502 | 97.69 |
| 6.4. 뉴스심리지수(실험적 통계) | A001 | 뉴스심리지수 | 20190503 | 99.68 |
| 6.4. 뉴스심리지수(실험적 통계) | A001 | 뉴스심리지수 | 20190504 | 100.32 |
| 6.4. 뉴스심리지수(실험적 통계) | A001 | 뉴스심리지수 | 20190505 | 100 |
| 6.4. 뉴스심리지수(실험적 통계) | A001 | 뉴스심리지수 | 20190506 | 100.18 |
뉴스심리지수는 2019년 5월 5일을 기준점(100)으로, 이보다 지수가 작으면 뉴스의 논조가 전반적으로 부정적이라는 것이고, 지수가 크면 논조가 전반적으로 긍정적이라고 해석됩니다.
작업환경
1) 윈도우10
2) 파이썬3.6(64-bit)
3) 파이썬IDE는 jupyter notebook
코드
▼ 한국은행이 제공하는 API 중, <통계 조회 조건 설정> API를 호출하는 함수를 정의합니다. 코드 재활용이 용이하기 때문에 저는 이렇게 '함수'로 정의하여 코딩하는 것을 선호합니다.
def get_product(KEY, STAT_CD, PERIOD, START_DATE, END_DATE):
# 파이썬에서 인터넷을 연결하기 위해 urllib 패키지 사용. urlopen함수는 지정한 url과 소켓 통신을 할 수 있도록 자동 연결해줌
import requests
from bs4 import BeautifulSoup
import pandas as pd
from lxml import html
from urllib.request import Request, urlopen
from urllib.parse import urlencode, quote_plus, unquote
import pprint
url = 'http://ecos.bok.or.kr/api/StatisticSearch/{}/xml/kr/1/30000/{}/{}/{}/{}/' \
.format(KEY # 인증키
, STAT_CD # 추출할 통계지표의 코드
, PERIOD # 기간 단위
, START_DATE # 데이터 시작일
, END_DATE) # 데이터 종료일
response = requests.get(url).content.decode('utf-8')
xml_obj = BeautifulSoup(response, 'lxml-xml')
# xml_obj
rows = xml_obj.findAll("row")
return rows
▼ API에서 요구하는 파라미터를 정의합니다. data_dict에는 여러 통계지표를 잔뜩 집어넣을 수도 있습니다. 다만 파라미터값을 '통계지표 코드'로 받기 때문에 미리 한국은행 오픈API 웹페이지에서 원하는 통계지표의 코드를 확인해야 합니다. 또 한꺼번에 추출하려는 통계지표의 분석의 기간 단위(PERIOD)가 동일해야 합니다.
참고로 'D'는 일 단위 통계라는 것인데, 아쉽게도 경제통계지표 중 일 단위로 제공되는 것은 거의 없습니다.
# 파라미터 정의
# 추출하고자 하는 통계지표 disc type - {통계지표 코드: 통계지표명}
data_dict = {
'521Y001' : '뉴스심리지수'
}
# 인증키
KEY = '한국은행에서 발급 받은 인증키'
# 그외 파라미터
PERIOD = 'D'
START_DATE = '20050101'
END_DATE = '20221231'
▼ 본격적인 코딩을 하려면 API의 명세를 이해해야 하는데, 귀찮으시면 그냥 아래 코드 그대로 따라하셔도 됩니다. <통계 조회 조건 설정> API가 제공하는 출력값 중에 원하는 항목들을 리스트 형태로 정리하고 for loop 구문을 통해 하나 하나 불러와 리스트로 저장하는 거예요.
2005년 1월 1일부터 2022년 12월 31일까지의 데이터를 호출했더니 총 6,387의 레코드를 가진 데이터가 반환되었네요.
# API의 반환(출력)값 중 저장하고자 하는 항목(item) 리스트
item_list = [
'STAT_CODE' # 통계표코드
, 'STAT_NAME' # 통계명
, 'ITEM_CODE1' # 통계항목1코드
, 'ITEM_NAME1' # 통계항목명1
, 'ITEM_CODE2' # 통계항목2코드
, 'ITEM_NAME2' # 통계항목명2
, 'ITEM_CODE3' # 통계항목3코드
, 'ITEM_NAME3' # 통계항목명3
, 'UNIT_NAME' # 단위
, 'TIME' # 시점
, 'DATA_VALUE'# 값
]
# 결과치를 담을 빈 리스트 생성
result_list = list()
# API를 순차적으로 호출하고 값을 담는 for loop 구문
for k in data_dict.keys():
rows = get_product(KEY, k, PERIOD, START_DATE, END_DATE)
print(len(rows)) # 수집해야 할 데이터의 row가 총 몇 개인지 출력
for p in range(0, len(rows)):
info_list = list()
for i in item_list:
try:
individual_info = rows[p].find(i).text # 만약 반환 중 error가 발생하면
except:
individual_info = "" # 해당 항목은 공란으로 채운다
info_list.append(individual_info)
result_list.append(info_list)
result_list
▼ 저장된 리스트를 데이터프레임으로 형태 변환합니다. 이 때 컬럼명도 내가 원하는 대로 지정할 수 있습니다.
import pandas as pd
from pandas import DataFrame
from datetime import datetime
# 결과 리스트를 DataFrame으로 변환 + 컬럼명 지정
result_df = DataFrame(result_list, columns=[
'통계표코드'
, '통계명'
, '통계항목1코드'
, '통계항목명1'
, '통계항목2코드'
, '통계항목명2'
, '통계항목3코드'
, '통계항목명3'
, '단위'
, '시점'
, '값'
]).drop_duplicates() # 중복된 row 제거
result_df
▼ 이 데이터프레임을 엑셀파일로 저장합니다.
# 엑셀로 저장
date = datetime.today().strftime('%Y-%m-%d')
result_df.drop_duplicates() \
.to_excel(date+'_korea bank indicators.xlsx', index = False)'Programming > Code Archive' 카테고리의 다른 글
| [파이썬] 실시간급상승검색어 자동 발송하는 봇 만들기 1: 텔레그램 봇 생성 (0) | 2023.08.13 |
|---|---|
| [파이썬] 인스타그램 해쉬태그(#) 검색결과 크롤링하기_최신ver. (19) | 2022.08.13 |
| [파이썬] 개편된 구글 플레이 스토어! 앱 리뷰 크롤링 (14) | 2022.06.21 |
| 전체 상장기업 재무제표 조회방법(feat. 파이썬으로 DART API 호출) (12) | 2022.05.11 |
| 파이썬 streamlit으로 데이터 시각화 웹어플리케이션 배포하기 (0) | 2022.05.09 |




댓글