퀀트투자 혹은 종목 스크리닝을 자체적으로 해보려고 툴을 만들었는데요. 이 때 필요한 것이 상장기업 전체에 대한 재무정보 혹은 재무제표입니다. 전체 상장기업의 데이터를 얻는 가장 일반적인 방법은 웹 크롤링일 텐데, 재무제표를 확인할 때 널리 이용하는 Company guide(Fn guide)나 네이버 증권 등의 재무제표 페이지에 접속해 파이썬 웹 스크래핑 라이브러리(Request나 Selenium)를 이용해 해당 페이지의 데이터를 긁어오는 겁니다.
저도 일찍이 컴패니 가이드의 재무제표 데이터를 수집하는 코드를 작성해 공유한 바 있습니다.
Company Guide(Fn Guide) 전종목 재무제표 크롤링
[퀀트투자를 위한 툴 만들기 2] Company Guide(Fn Guide)에서 종목 재무정보 추출
파이선과 엑셀 Xlwings 패키지를 활용해 퀀트투자를 위한 종목선정 툴을 만들었습니다. [퀀트투자를 위한 툴 만들기 0] 파이썬과 엑셀을 활용한 종목 선정 프로그램 기획 계량적인 방식으로 주식
mokeya.tistory.com
이번 포스팅에서 소개할 방식은 웹 크롤링보다 안정적이고 떳떳하게 데이터를 수집하는 방법입니다. 바로 API를 이용하는 것인데요, 전자공시시스템(DART)에서 제공하는 오픈API로 국내 상장기업의 전체 재무제표를 스크래핑하는 코드입니다.
코딩의 결과
다트에서 오픈API로 제공하는 재무제표는 두 가지입니다. 상세 버전과 간략 버전이라고 생각하면 되는데요. 상세버전은 대차대조표(BS), 포괄손익계산서(CIS), 현금흐름표(CF)의 모든 계정들이 포함되어 있고 아래와 같이 생겼습니다.

간략버전은 대차대조표(BS), 포괄손익계산서(IS)의 주요 계정만 제공하고 있기 때문에 깊이 있는 재무분석에 동원하기에는 무리가 있습니다. 이렇게 생겼습니다.

간략버전이 제공하는 계정의 수는 적지만 상세버전이 갖지 못하는 장점이 확실히 있습니다.
1) 종목에 상관 없이 제공되는 계정명이 동일합니다(대신 주요 계정만 제공). 이에 반해 상세버전은 기업이 제출한 재무제표의 계정명이 원본 그대로 들어가 있습니다. 가령 어떤 제조기업의 재무제표(내 포괄손익계산서)에서는 '매출액'이라고 표현된 계정이 IT 기업인 NAVER의 재무제표에서는 '영업수익'으로 표시되어 있는 경우가 있습니다. 이러면 전체 상장 종목들을 놓고 지표별로 비교할 때 복잡한 전처리를 거쳐야 할 수도 있습니다.
2) 간략버전에는 기업의 주식시장 종목코드가 제공되는 반면, 상세버전의 재무제표에는 주식시장 종목코드가 제공되지 않습니다. 재무제표'만' 가지고 투자 분석을 수행할 것이라면 상관 없지만, 제3의 소스로부터 얻은 여러 가지 투자지표들을 붙여서(전문용어로는 JOIN 혹은 MERGE) 종목을 분석하려는 경우엔 종목코드의 부재가 크나큰 단점이 될 수 있습니다. 왜냐하면 증권사 API나 주식 관련 사이트에서는 특정 종목을 식별하기 위해 종목코드를 보편적으로 사용합니다. 그러니 재무제표와 그런 타출처의 데이터를 엮으려면 종목코드가 양쪽 모두에 존재해야 하는 거지요.
준비사항
파이썬이 이미 설치되어 있고, 기본적인 코딩 지식이 있다는 가정 하에, 준비해야 할 것은 오직 하나. 다트 오픈API 인증키를 발급 받는 것입니다.
DART 오픈API 페이지에서 들어가서 아래와 같이 인증키를 신청하시면 됩니다.
제 기억에 인증키는 신청하자마자 바로 발급되었던 것 같습니다. 발급 받은 인증키를 어디다가 잘 메모해두세요. API 호출시 필수 입력값으로 사용됩니다.
코드
재무제표 API는 기업고유번호를 입력값으로 받기 때문에 출력하고 싶은 기업의 번호를 알아야 합니다. 모든 상장기업의 재무제표를 뽑고자 한다면 당연히 모든 상장기업의 기업고유번호를 알아야 하겠지요. 이 고유번호를 말아놓은 API도 DART에서는 제공하고 있기 때문에 먼저 해당 API를 호출해, 우리가 수집하려는 상장기업의 기업고유번호를 정리해둡니다.
import requests
from io import BytesIO
from zipfile import ZipFile
from xml.etree.ElementTree import parse
from bs4 import BeautifulSoup
import pandas as pd
from lxml import html
from urllib.request import Request, urlopen
from urllib.parse import urlencode, quote_plus, unquote
KEY = '발급 받은 인증키 값'
url = 'https://opendart.fss.or.kr/api/corpCode.xml'
params ={'crtfc_key' : KEY}
response = requests.get(url, params=params).content
with ZipFile(BytesIO(response)) as zipfile:
zipfile.extractall('corpCode')
# xml 호출하여 읽어오기
xmlTree = parse('corpCode\corpCode.xml')
root = xmlTree.getroot()
raw_list = root.findall('list')
corp_list = []
for l in range(0, len(raw_list)):
corp_code = raw_list[l].findtext('corp_code')
corp_name = raw_list[l].findtext('corp_name')
stock_code = raw_list[l].findtext('stock_code')
modify_date = raw_list[l].findtext('modify_date')
corp_list.append([corp_code, corp_name, stock_code, modify_date])
print(l)
위 코드의 결과, 기업의 고유번호, 기업명, 주식시장 종목코드, 최종 변경일자가 list 형태로 저장됩니다. 이 list를 판다스(pandas) 데이터프레임(DataFrame) 형태로 변형하겠습니다(아래 코드 참고).
from pandas import DataFrame
from datetime import datetime
corp_df = DataFrame(corp_list, columns=[
'고유번호'
, '정식명칭'
, '종목코드'
, '최종변경일자'
])
corp_df.head()
위 결과물에서 보다시피 (주식시장) 종목코드 컬럼이 텅 비어 있는 애들도 많이 있습니다. 공개시장에 상장한 기업이 아니란 이야기이지요. 주식투자 분석 목적으로 재무제표를 수집하려는 우리에게는 관심 대상이 아닙니다. 이런 기업들은 걸러내고 상장기업의 데이터만 필터링해보겠습니다.
아래 코드 수행 결과 종목코드 컬럼에 값이 존재하는, 즉 상장된 기업들의 기업고유번호만 데이터프레임에 남게 됩니다.
import pandas as pd
corp_df = pd.read_excel('C:\\Users\\USER\PycharmProjects\\2022-05-02_corp list.xlsx')
stock_df = corp_df[corp_df['종목코드'] != " "]
# stock_df.head()
stock_df = stock_df[['고유번호', '정식명칭', '종목코드']].drop_duplicates()
stock_df.head(10)
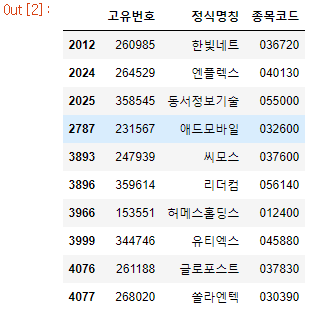
재무제표 API를 호출하기 위해 필요한 기업고유번호도 정리가 되었으니, 이제 본격적으로 전체 상장기업의 재무제표 API를 호출할 차례입니다. 해당 API이 어떤 입력값을 요하는지, 출력값은 어떤 형식(스키마)인지 꼼꼼히 확인한 후 우리에게 필요한 출력값을 list로 저장하는 함수를 정의했습니다. 이 함수는 특정 기업의 고유번호를 입력 받아 그 기업의 재무제표 주요 계정 값을 list로 반환합니다.
이 함수는 인증키값(KEY), 수집하려는 기업의 고유번호(CORP_CODE), 대상 연도(YEAR), 보고서 종류(RPT_CODE: 1분기 보고서/ 반기 보고서/ 3분기 보고서/ 연간보고서) 네 가지의 파라미터를 입력 받습니다.
# Defining a function to scrap data
def get_items(KEY, CORP_CODE, YEAR, RPT_CODE):
# 파이썬에서 인터넷을 연결하기 위해 urllib 패키지 사용. urlopen함수는 지정한 url과 소켓 통신을 할 수 있도록 자동 연결해줌
import requests
from bs4 import BeautifulSoup
import pandas as pd
from lxml import html
from urllib.request import Request, urlopen
from urllib.parse import urlencode, quote_plus, unquote
url = 'https://opendart.fss.or.kr/api/fnlttSinglAcnt.xml'
params ={'crtfc_key' : KEY
, 'corp_code' : CORP_CODE
, 'bsns_year' : YEAR
, 'reprt_code' : RPT_CODE}
response = requests.get(url, params=params).content.decode('UTF-8')
# html을 파싱할 때는 html.parser를
# xml을 파싱할 때는 lxml-xml을 사용
xml_obj = BeautifulSoup(response, 'html.parser')
rows = xml_obj.findAll("list")
return rows
네 가지 파라미터를 아래와 같이 지정하여 데이터를 수집하겠습니다. 저는 2021년 연도 사업보고서를 스크래핑하기 위해 아래처럼 파라미터를 지정하였고요, 만약 다른 연도, 다른 종류의 보고서가 필요하시다면 파라미터 값만 적절히 바꿔주시면 됩니다.
기업고유번호를 한 개씩 넣어가며 한 개 기업의 재무제표를 저장하고, 그 다음 기업의 재무제표를 저장하고... 하는 식으로 함수가 구동되도록 for loop 구문을 작성했어요.
KEY = '발급 받은 인증키값'
YEAR = '2021'
RPT_CODE = '11011' # 1분기보고서 : 11013 반기보고서 : 11012 3분기보고서 : 11014 사업보고서 : 11011
corp_list = stock_df['고유번호'].to_list()
item_list = [
'bsns_year'
, 'stock_code'
, 'reprt_code'
, 'fs_div' # CFS: 연결재무제표, OFS: 재무제표
, 'sj_div'
, 'account_nm'
, 'thstrm_nm'
, 'thstrm_dt'
, 'thstrm_amount'
, 'thstrm_add_amount'
, 'frmtrm_nm'
, 'frmtrm_dt'
, 'frmtrm_amount'
, 'frmtrm_add_amount'
, 'bfefrmtrm_nm'
, 'bfefrmtrm_dt'
, 'bfefrmtrm_amount'
, 'currency'
]
fs_list = []
for c in corp_list:
CORP_CODE = str(c).zfill(8)
items = get_items(KEY, CORP_CODE, YEAR, RPT_CODE)
for i in range(0, len(items)):
fs_item_list = []
for item in item_list:
try:
value = items[i].find(item).text
except:
value = ''
fs_item_list.append(value)
fs_list.append(fs_item_list)
print(CORP_CODE)위의 코드는 결과값을 list 형태로 저장하고 있기 때문에 해당 데이터를 우리가 친숙한, 테이블(판다스 데이터프레임) 형태로 바꿔주었습니다. 컬럼명도 원하는 대로 지정해주고요.
# import pandas
import pandas as pd
from pandas import DataFrame
from datetime import datetime
fs_df = DataFrame(fs_list, columns=[
'사업연도'
,'종목코드'
,'보고서코드'
,'연결/개별구분'
,'재무제표구분'
,'계정명'
,'당기명'
,'당기일자'
,'당기금액'
,'당기누적금액'
,'전기명'
,'전기일자'
,'전기금액'
,'전기누적금액'
,'전전기명'
,'전전기일자'
,'전전기금액'
,'통화'
])
fs_df.head(5)
마지막으로 위의 데이터프레임을 엑셀 파일(.xlsx)로 저장하고 마무리하겠습니다.
date = datetime.today().strftime('%Y-%m-%d')
fs_df.to_excel(YEAR+'_financial statements main accounts.xlsx', index=False)'Programming > Code Archive' 카테고리의 다른 글
| [파이썬-오픈API] 한국은행 경제통계지표 추출 (0) | 2022.07.02 |
|---|---|
| [파이썬] 개편된 구글 플레이 스토어! 앱 리뷰 크롤링 (14) | 2022.06.21 |
| 파이썬 streamlit으로 데이터 시각화 웹어플리케이션 배포하기 (0) | 2022.05.09 |
| 파이썬 Tesseract로 OCR(광학식 문자 판독기) 구현하기 (2) | 2022.05.08 |
| 미국 주식 재무제표 크롤링으로 배우는 파이썬 Selenium 기초 (0) | 2022.05.08 |




댓글