보통 파이썬으로 데이터 시각화 대시보드를 만들거나 머신러닝 앱을 빌드해 온라인으로 배포한다고 하면 쟝고나 플라스크를 떠올리기 마련입니다. 그런 프레임워크들을 사용함으로써 얻을 수 있는 이점은 분명 존재합니다. 그러나 그 프레임워크가 사용자 친화적인지, 빠른지, 코드를 간략하게 작성하고자 하는 개발자에게도 적합한지 물으면 자신 있게 그렇다고 대답하긴 어렵습니다. 즉, 재빠르게 머신러닝 어플리케이션을 선보여야 하는 프로젝트나 몇 명 되지도 않는 소규모 팀에서 쟝고나 플라스크 개발자를 따로 두어야 할 이유가 없다는 말입니다. 언급한 상황이라면 ‘Streamlit’이 훌륭한 대안이 될 수 있습니다.
Streamlit이란?
Streamlit은 머신러닝이나 데이터 사이언스에 특화된 웹 어플리케이션을 쉽게 만들고 공유하도록 해주는 파이썬 오픈소스 라이브러리입니다. 몇 분만 투자하면 여러분도 강력한 데이터 어플리케이션을 빌드하고 배포할 수 있습니다.
Streamlit의 강점
- 학습곡선이 거의 없다고 봐도 될 정도로 배우기 쉽다
- 사용자, 즉 개발자 친화적이다
- 빌드업에 시간을 많이 안 써도 된다
- 시각화에 서드파티 툴을 활용할 수 있다
- 그 외에도 많다
위에도 언급했지만, Streamlit을 활용하면 데이터 시각화 앱을 쉽게 빌드할 수 있습니다. 고작 몇 시간입니다. 몇 시간이면 데이터 앱을 만들 수 있습니다. 파이썬 코딩 작성이 능숙한 편이 아니라면 쟝고를 세팅하고 배우는 건 힘듭니다. 난이도로 따지면,
쟝고 >> 플라스크 >> Streamlit 정도 되겠습니다.
프로젝트 개요
시각화에 필요한 데이터는 공공API를 통해 수집했습니다. 데이터의 변형은 최소화하고 요청이 있을 때에 필요한 데이터만 호출했습니다. 차트는 기본적으로 Plotly를 사용해 그렸습니다. 제공하는 기능을 최대한으로 사용하되 단순하고 신속하게 만드는 걸 목표로 삼았습니다.
가급적 포스팅 길이는 단촐하게 가려고 모든 코드는 GitHub에 올려두었습니다. 마음대로 편집하셔도 됩니다. 웹 어플리케이션은 여기서 보실 수 있습니다.
작업 전
- streamlit은 pip pip install streamlit 으로 설치하면 됩니다. 윈도우 외 다른 OS에서는 이 문서를 참고하세요.
- 설치가 정상적으로 되었는지 확인하려면 streamlit hello를 command prompt에서 실행해보세요. 기본 브라우저 localhost:8501에서 열릴 겁니다. 공식문서가 몇 가지 샘플 데모와 함께 열립니다. (놀라운 데모들이 많으니 꼭 한 번 실행해보시길 추천합니다)
어플리케이션 빌드
설치가 성공적으로 완료됐다면 이제 어플리케이션의 실체를 구현하고 streamlit의 마법을 경험할 차례입니다. 저는 코드 에디터를 위해 sublime_text를 사용했지만 여러분은 다른 에디터를 사용하실 수 있습니다.
제가 사용한 데이터셋은 이겁니다. TFL 데이터셋은 오픈소스 실시간 API로 제공됩니다. API로부터 데이터 추출하는 과정 간단하게 설명드리겠습니다.
1단계 : request 라이브러리를 사용해 API로부터 데이터를 추출
import requests as r
def get_data(url):
api = r.get(url)
api_status_code = api.status_code #200
api_data = api.json() #converting into json format
api_data_normal = pd.json_normalize(api_data) #converting into dataframe
return api_data_normal
get_data('https://api.tfl.gov.uk/AccidentStats/2019')
2단계 : URL을 변환해 API 데이터를 json 포맷으로 변형하고 이어서 데이터프레임으로까지 변환했다면 이제 형변환을 하셔야 합니다. 아래가 데이터 형변환을 위한 코드입니다.
api_data_normal = get_data()
api_casualities = pd.json_normalize(api_data_normal['casualties'])
api_casualities_col = pd.json_normalize(api_casualities[0])
#api_casualities_col['$type'][0]
api_casualities_col = api_casualities_col.drop(columns = '$type')
casuality_cols = api_casualities_col.columns
age = pd.Series(api_casualities_col['age'], name = 'age')
casualities_class = pd.Series(api_casualities_col['class'], name = 'class')
severity = pd.Series(api_casualities_col['severity'], name = 'severity')
mode = pd.Series(api_casualities_col['mode'], name = 'mode')
ageBand = pd.Series(api_casualities_col['ageBand'], name = 'ageBand')
api_vehicles = pd.json_normalize(api_data_normal['vehicles'])
api_vehicles_col = pd.json_normalize(api_vehicles[0])
api_vehicles_col = pd.Series(api_vehicles_col['type'], name = 'vehicles')
api_data_normal = api_data_normal.drop(columns = ['$type','casualties', 'vehicles'])
api_data_modified = pd.concat([api_data_normal,age, casualities_class, mode, ageBand, api_vehicles_col], axis=1)
class_dict = dict(api_data_modified['class'].value_counts())
class_df = pd.DataFrame(class_dict.items(), columns = ['class', 'count'])
mode_dict = dict(api_data_modified['mode'].value_counts())
mode_df = pd.DataFrame(mode_dict.items(), columns = ['mode', 'count'])
age_dict = dict(api_data_modified['age'].value_counts())
age_df = pd.DataFrame(age_dict.items(), columns = ['age', 'count'])
drop_cols = ['id', 'location', 'date', 'severity', 'borough', 'age', 'class', 'mode', 'ageBand', 'vehicles']
map_df = api_data_modified.drop(columns = drop_cols)
3단계 : 데이터 형변환이 끝나면 이제 streamlit의 기능을 사용할 때입니다. 차트를 그리기 위한 ‘containers’, ‘sidebars’, ‘plotly’와 폰트를 위한 툴인 ‘subheaders’, ‘markdown’, ‘title’과 같은 기능을 사용하게 됩니다. 제가 언급한 것은 일부이고요, 여기에 우리 웹 앱을 더 이쁘고 기능적으로 가꾸기 위해 사용할 수 있는 다양한 기능들이 망라되어 있습니다. 참고해보세요. 얼마나 간단하게 컨테이너 생성하는지 한 번 보여드리겠습니다. 컨테이너는 우리 콘텐트가 웹페이지 내에서 적절하게 위치하고 배열되도록 도와줍니다.
import streamlit as st
dataExploration = st.container()
with dataExploration:
st.title('Transport for London')
st.subheader('Keeping London moving...')
st.header('Dataset: Transport for London')
st.markdown('I found this dataset at... https://tfl.gov.uk/info-for/open-data-users/')
st.markdown('**Basically, it is a "London AccidentStats" dataset for the year 2019**')
st.text('Below is the sample DataFrame')
st.write(api_data_modified.head())
위의 코드 스니펫에서 볼 수 있는 것처럼, streamlit을 임포트합니다. 그 다음 컨테이너를 생성했습니다. 컨테이너에는 ‘title(큰 사이즈로 굵게 표현되는 페이지의 제목), ‘subheader’, ‘header’, ‘markdown’, ‘text’, ‘write’과 같이 다양한 필요를 충족시켜줄 수 있는 빌트인 기능이 존재합니다. 우리 데이터셋을 dataframe 형식으로 웹페이지에 노출시킬 수도 있지만 너무 행이 많기 때문에 데이터셋을 전체적으로 조망하기에는 무리가 있습니다. 때문에 .head()를 사용해 첫 다섯 개 행만 보이도록 조치했습니다.
개발 과정 중간중간 우리가 만든 웹 콘텐트를 확인하려면 stram run app_name.py 코드를 command prompt에 실행하면 됩니다. 단 어플리케이션이 위치한 폴더와 동일한 폴더 내에 위치해 있어야 합니다. 당신이 설정한 기본 브라우저로 localhost: 8501이 열릴 겁니다. 웹 앱의 코드를 수정할 때마다 run을 직접 실행하거나, rerun always를 선택해 자동으로 페이지가 재실행되도록 할 수도 있습니다. 웹 어플리케이션 우상단에 해당 옵션이 보이실 겁니다.
위의 과정과 유사하게, 저는 ‘Plotly’로 만든 차트를 보여줄 또다른 컨테이너를 생성했습니다. 이 과정 역시 매우 단순하고 쉽습니다. 기억할 건 st.plotly_chart()밖에 없습니다. 컨테이너 안에 생성한 plotly 차트 샘플 아래 코드 참고하세요.
severity_viz = st.container()
with severity_viz:
st.header('Severity wise AccidentStats')
st.text('A pie chart depicting the count of accident severity')
severity_plot = px.pie(api_data_modified, values='id', names='severity')
st.plotly_chart(severity_plot)
지도에 경도, 위도 데이터를 표현하기 위해서 내장되어 있는 매핑 기능도 사용했습니다.
map_con = st.container()
drop_cols = ['id', 'location', 'date', 'severity', 'borough', 'age', 'class', 'mode', 'ageBand', 'vehicles']
map_df = api_data_modified.drop(columns = drop_cols)
with map_con:
st.header('A simple map of the accident zones in london')
st.map(map_df, use_container_width = True)
그리고 웹페이지를 찾아준 분들께 인사를 건네기 위해 사이드바도 활용했습니다.
마지막으로 @st.cashe라 불리는 특별한 기능도 사용했습니다. 우리 웹 앱의 캐쉬를 생성해주는 기능입니다. 앱을 실행할 때마다 데이터셋을 로딩해야 한다면 에너지와 시간이 그만큼 더 소요될 텐데, 이를 줄여줍니다.
@st.cache
def get_data():
api = r.get('https://api.tfl.gov.uk/AccidentStats/2019')
api_status_code = api.status_code
api_data = api.json()
api_data_normal = pd.json_normalize(api_data)
cols = api_data_normal.columns
return api_data_normal
4단계 : 별거 없지만 아주 중요한 단계입니다. 웹 어플리케이션을 배포하는 단계입니다. 결국 웹 어플리케이션을 빌드한다면 그 이유는 누군가와 그것을 공유하기 위함이 아니겠습니까. 초심자에겐 배포에 대한 막연한 두려움이 있지만 streamlit은 그들 서버에 당신의 웹 앱을 배포할 수 있도록 호스팅을 제공할 뿐 아니라 심지어 돈도 받지 않습니다.
그냥 streamlit 웹사이트에서 구글 혹은 깃허브 계정으로 가입만 하면 되는데, 아무래도 여러분들의 코드가 github에 있을 테니 github로 가입하시는 게 좋겠지요?
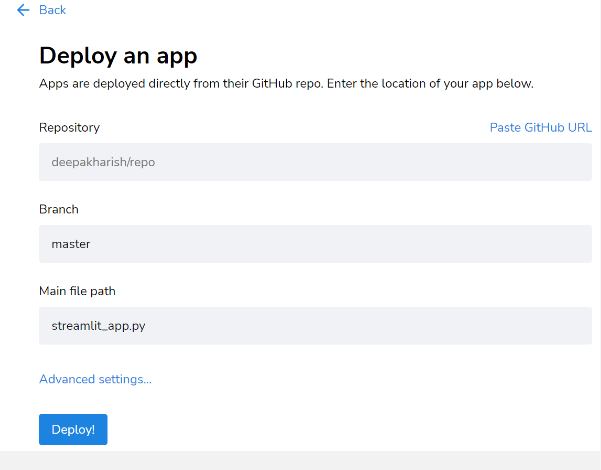
- 먼저 pipregs를 사용해 requirements.txt 파일을 만듭니다.
- requirements.txt에 따라 앱을 github에 업로드합니다.
- streamlit 배포 페이지 내 우측에 위치한 “new app” 버튼을 클릭합니다.
- 앱 코드가 위치한 github 저장소의 링크를 붙여넣습니다.
- “Deploy”를 클릭합니다. 몇 분 뒤 앱이 배포됩니다.
'Programming > Code Archive' 카테고리의 다른 글
| [파이썬] 개편된 구글 플레이 스토어! 앱 리뷰 크롤링 (14) | 2022.06.21 |
|---|---|
| 전체 상장기업 재무제표 조회방법(feat. 파이썬으로 DART API 호출) (12) | 2022.05.11 |
| 파이썬 Tesseract로 OCR(광학식 문자 판독기) 구현하기 (2) | 2022.05.08 |
| 미국 주식 재무제표 크롤링으로 배우는 파이썬 Selenium 기초 (0) | 2022.05.08 |
| FOMC 회의 발표 스크립트 확인 방법과 출현 단어 분석 (0) | 2022.05.06 |




댓글