인스타그램 해쉬태그 검색결과 크롤링하는 코드를 올렸었어요, 감사하게도 많은 분들이 참고해주셨는데 Meta에서 마크업을 계속 수정하다보니까 코드가 작동 안 한다는 민원이 계속 접수되더군요. 그 때마다 코드를 수정하는 식으로 응대를 하다가 저도 현업이 있는 사람이다보니 어느 시점 이후로는 팔로우업을 못 하겠더라고요.
지금 올리는 수정 코드를 마지막으로 인스타그램 해쉬태그 크롤링 코드에 대한 A/S는 없을 예정입니다. 혹시 크롤링이 필요하신 분은 비밀댓글 주세요. 싸게 해드릴게요...
아래 정리한 코드는 글이 작성된 오늘까지도 제대로 작동되는 걸 확인한 코드입니다. 수정 요청은 받지 않습니다.
결과물 형태
-
아래 스크린샷처럼 본문 텍스트, 작성일, 좋아요 수, 장소, 삽입된 태그가 엑셀로 정리돼 저장되는 코드입니다.
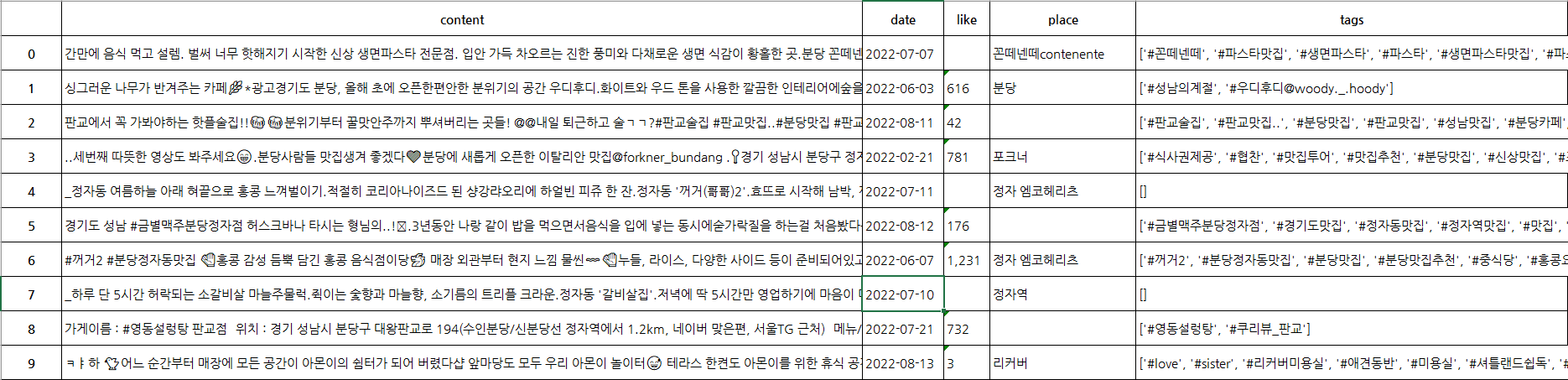
코드
-
셀레니움 패키지를 사용하기 때문에 크롬드라이버를 설치하셔야 됩니다. 본 포스팅에서는 그에 대해서는 별도로 가이드 하지 않습니다. 모르시는 분들은 이전에 올렸던 포스팅에서 해당 내용 참고하시면 좋을 것 같아요.
[파이썬Python] 인스타그램 해쉬태그(#) 검색결과 크롤링하기
★ 댓글로 주신 의견 반영하여 코드는 지속적으로 수정하고 있습니다. 수정된 부분은 아래 본문에 일일이 표시해두었으니 참고해주세요. 댓글 주신 모든 분들 감사합니다. 셀레니움의 기초 이
mokeya.tistory.com
아래 코드 스니펫을 하나씩, 앞의 스니펫이 실행완료된 걸 확인하고 다음으로 넘어가고, 하는 식으로 활용하시면 되겠습니다.
01
# 필요 패키지 호출
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import re
import time
02
# 함수 정의: 검색어 조건에 따른 url 생성
def insta_searching(word):
url = "https://www.instagram.com/explore/tags/" + str(word)
return url
03
# 함수 정의: 열린 페이지에서 첫 번째 게시물 클릭 + sleep 메소드 통하여 시차 두기
def select_first(driver):
first = driver.find_elements_by_css_selector("div._aagw")[0]
first.click()
time.sleep(3)
04
# 함수 정의: 본문 내용, 작성일자, 좋아요 수, 위치 정보, 해시태그 가져오기
import re
from bs4 import BeautifulSoup
def get_content(driver):
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
# 본문 내용
try:
content = soup.select('div._a9zs')[0].text
except:
content = ''
# 해시태그
tags = re.findall(r'#[^\s#,\\]+', content)
# 작성일자
date = soup.select('time._aaqe')[0]['datetime'][:10]
# 좋아요
try:
like = soup.select('div._aacl._aaco._aacw._aacx._aada._aade')[0].findAll('span')[-1].text
except:
like = 0
# 위치
try:
place = soup.select('div._aaqm')[0].text
except:
place = ''
data = [content, date, like, place, tags]
return data
05
# 함수 정의: 첫 번째 게시물 클릭 후 다음 게시물 클릭
def move_next(driver):
right = driver.find_element_by_css_selector("div._aaqg._aaqh") # 2022/01/11 수정
right.click()
time.sleep(3)
06 인스타그램 열고 로그인. 검색어 입력
# 크롤링 시작
"""
driver.get(url)을 통해 검색 페이지 접속하고,
target 변수에 크롤링할 게시글의 수를 바인딩
"""
# 크롬 브라우저 열기
driver = webdriver.Chrome('chromedriver.exe')
driver.get('https://www.instagram.com')
time.sleep(3)
# 인스타그램 로그인을 위한 계정 정보
email = # 로그인ID
input_id = driver.find_elements_by_css_selector('input._2hvTZ.pexuQ.zyHYP')[0]
input_id.clear()
input_id.send_keys(email)
password = # 로그인 비번
input_pw = driver.find_elements_by_css_selector('input._2hvTZ.pexuQ.zyHYP')[1]
input_pw.clear()
input_pw.send_keys(password)
input_pw.submit()
time.sleep(5)
# 게시물을 조회할 검색 키워드 입력 요청
word = input("검색어를 입력하세요 : ")
word = str(word)
url = insta_searching(word)
07 인스타그램 게시물 크롤링 수행
# 검색 결과 페이지 열기
driver.get(url)
time.sleep(10) # 코드 수행 환경에 따라 페이지가 로드되는 데 시간이 더 걸릴 수 있어 8초로 변경(2022/01/11)
# 첫 번째 게시물 클릭
select_first(driver)
# 본격적으로 데이터 수집 시작
results = []
## 수집할 게시물의 수
target = 10
for i in range(target):
try:
data = get_content(driver)
results.append(data)
move_next(driver)
except:
time.sleep(2)
move_next(driver)
time.sleep(5)
print(results[:2])Output

08 결과 엑셀파일로 저장
# 결과를 데이터프레임으로 저장
import pandas as pd
from datetime import datetime
date = datetime.today().strftime('%Y-%m-%d')
results_df = pd.DataFrame(results)
results_df.columns = ['content','date','like','place','tags']
results_df.to_excel(date + '_about '+word+' insta crawling.xlsx')
'Programming > Code Archive' 카테고리의 다른 글
| [파이썬] 실시간급상승검색어 자동 발송하는 봇 만들기 2: 실급검 크롤링 (0) | 2023.08.13 |
|---|---|
| [파이썬] 실시간급상승검색어 자동 발송하는 봇 만들기 1: 텔레그램 봇 생성 (0) | 2023.08.13 |
| [파이썬-오픈API] 한국은행 경제통계지표 추출 (0) | 2022.07.02 |
| [파이썬] 개편된 구글 플레이 스토어! 앱 리뷰 크롤링 (14) | 2022.06.21 |
| 전체 상장기업 재무제표 조회방법(feat. 파이썬으로 DART API 호출) (12) | 2022.05.11 |




댓글