싱가폴 출신의 데이터 사이언티스트, Travis Tang님의 아티클을 번역한 글입니다.
데이터 사이언티스트 wannabe라면, 일독할 가치가 충분한 글입니다.
Travis Tang님은 화학공학을 전공했지만 테크기업에서 데이터 분석가로 사회생활을 시작했습니다.
몇 차례에 걸쳐 포스팅 될 그의 이 아티클은 화학공학도가
데이터 사이언티스트로 일하기까지의 여정과 필요한 스킬셋(skill set)을 구체적으로 담고 있습니다.
Tang은, 데이터 사이언티스트로 나아가는 데 필요한 정보는 홍수처럼 넘치는데
오히려 그 때문에 최고의 자원을 선별해내는 것이 어렵다고 토로합니다.그렇기 때문에 먼저 아래의 질문에 답을 할 수 있어야 한다고 강변합니다.
데이터 과학이란 무엇입니까?
아, 이것은 인사 담당자와 기업의 면접관 모두를 당황하게 만드는 대답하기 어려운 질문입니다. 사실, 회사마다 데이터 과학을 다르게 정의하여 용어가 모호하고 다소 이해하기 어렵습니다. 프로그래밍이라고 하는 사람도 있고 수학이라고 말하는 사람도 있고 데이터를 이해하는 일이라고 말하는 사람도 있습니다. 모두 어느 정도 맞는 말입니다. 나(Travis Tang)에게 가장 동의하는 정의는 다음과 같습니다.
데이터 사이언스data science는 수학, 컴퓨터 과학, 도메인 지식 분야에서 도출된 기술과 이론을 사용하는, 학제를 넘나드는(inter-disciplinary) 분야이다.
아래 그림은 위의 정의를 잘 보여주는 이미지입니다.
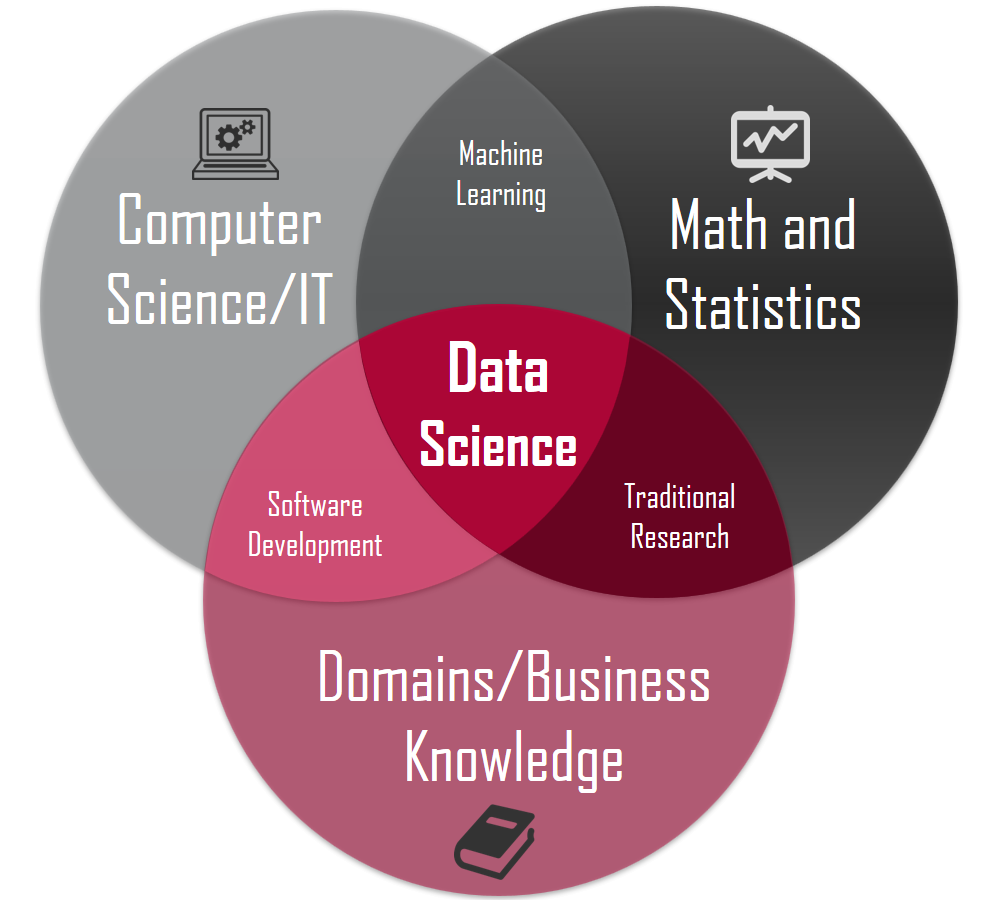
데이터 사이언스는 다양한 학문들의 교차로
이 이미지에서 각 분야의 지식이 뭉쳐 데이터 과학을 형성한다는 것을 보여주기 위하여 분야 사이의 경계를 흐릿하게 묘사했습니다.
자, 그럼 데이터 사이언스, 데이터 과학을 배우기 위해선 뭘 해야 할까요?
일련의 게시물을 통해 저는 데이터 사이언티스트로 나아가는 과정에서 제가 배운 것들을 알려드리려 합니다. 이를 통해 저와 같은 입장에 있는 분들이 데이터 사이언스를 배워나가는 데에 도움이 되었으면 합니다. 이 아티클은 아래와 같은 내용으로 구성될 예정입니다.
1부 — SQL, Python 및 R을 사용한 데이터 처리
2부 — 수학, 확률 및 통계
3부 — 컴퓨터 과학 기초
4부 — 기계학습=머신러닝(본 게시물의 내용)
5부 — 첫 번째 기계 학습 프로젝트 구축
머신러닝이나 데이터 사이어스를 배우고 싶지만 어디서부터 시작해야 할지 막막하신가요? 저 역시 그랬습니다. 그리고 저는 제 시간을 가장 잘 사용할 수 있는 과정을 찾기 위해 인터넷을 뒤지며 긴 밤을 보낸 것을 기억합니다. 고된 검색 끝에 전 머신러닝 학습을 배우는 데 탁월한 리소스를 찾았고 그것들은 제가 무사히 면접을 치르고 데이터 사이언스 분야에취업하는 데에 큰 도움이 되었습니다. 이 게시물에서는 제가 요긴하게 활용했떤 머신러닝 코스를 공유하여 저와 같은 주제로 밤새고 계실 분들께 큰 도움을 드리려 합니다.

오늘날 머신러닝은 종종 전세계의 많은 문제에 대한 치트키로 선전되고 있습니다. 머신러닝의 도움으로 우리는 스마트해진 검색엔진, 자율주행 자동차, 실시간 음성인식의 이점을 누리고, 인간 게놈의 신비를 엄청나게 풀기까지 했습니다. 우리 일상생활에 머신러닝이 편재해있다는 사실은 머신러닝이 인간의 삶을 대규모로 개선할 수 있으리라는 가능성을 시사합니다. 머신러닝의 매력이 여기에 있습니다.
배우는 데 관심이 없는 외부인에게는 머신러닝이 막연한 유행어에 불과합니다. 기계학습을 시작하고자 하는 새내기들에게 기계학습은 진입장벽이 높은 난해한 개념처럼 보일 수 있습니다. 그러나 기계학습이 신비하거나 이해하기 어려울 필요는 없습니다. 만약 기계학습에 대한 지식을 쌓고자 하는 진정한 열망과 약간의 인내심만 있다면 당신은 기계학습을 시작할 완벽한 위치에 있습니다.
그런데, 머신 러닝이란 정확히 뭔데요?
저는 머신러닝을 기계가 스스로 학습하도록 가르치는 과학이라고 생각하고 싶습니다. 더 엄격하게 말하면 기계학습의 아버지인 Arthur Samuel은 1959년에 이를 다음과 같이 우아하게 정의했습니다.
명시적으로 프로그래밍하지 않고도 컴퓨터에 학습 능력을 부여하는 연구 분야 [1]
이것은 우리가 기존 프로그래밍을 정의한 것과는 완전히 다릅니다. 전통적인 프로그래밍에서 우리는 컴퓨터에 짜여진 규칙(program)와 입력(input)을 제공합니다. 차례로 우리는 출력(output)을 기대합니다. 예를 들어 계산기 프로그램에 1+1 입력을 제공하면 출력이 무엇인지 모두 알 수 있습니다.

기계학습은 컴퓨터에 일부 입력(input) 및 출력(output)을 제공합니다. 시간이 지남에 따라 기계는 입력과 출력 간의 관계를 더 잘 학습합니다. 새로운 입력을 제공하면 예측된 출력을 알려줄 수 있습니다. 예를 들어 Elon은 중고 Tesla를 구매할 계획입니다. 그는 Craigslist에서 Tesla 차량 가격에 대해 조사한 결과 거의 새 Tesla 차량이 약 40,000달러부터 시작한다는 것을 발견했습니다. 그는 또한 자동차가 1년이 될 때마다 Tesla 가격이 약 $1,000씩 떨어진다는 사실도 알고 있습니다. 그런 다음 그는 5년 된 자동차가 35,000달러라고 예측합니다.

다시 말해, Elon은 기계학습에서 중요한 개념인 회귀(regression)를 방금 발명했습니다! 기계학습에서 프로그램은 입력과 출력 사이의 패턴을 인식하고 출력을 예측합니다.

인공지능(AI, Artificial Intelligence)과 딥 러닝(Deep Learning)은 또 뭔데요?
머신러닝과 밀접한 관련이 있는 유행어들입니다. 서로의 관계는 정확히 무엇일까요? 이것은 아래 다이어그램에 잘 드러나 있습니다.
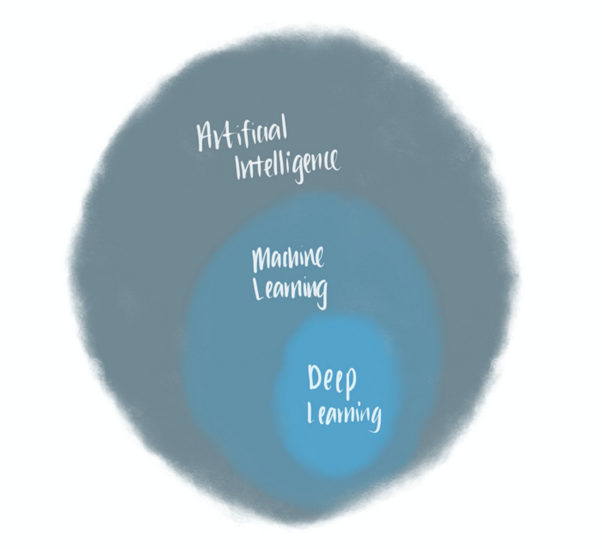
이 벤다이어그램에서 볼 수 있듯이 딥 러닝은 뇌가 뉴런에서 뉴런으로 정보를 전송하는 방식을 알고리즘으로 모방한 기계학습의 하위 집합입니다. 딥 러닝이 기계학습의 보다 고도화된 형태으로 간주될 때도 있습니다. 그러므로 사실 학습자는 딥 러닝에 뛰어들려 해도 결국 머신러닝의 기초를 이해해야만 합니다.
반면, 머신러닝은 인공지능(AI)의 하위 집합입니다. AI는 추론, 계획 및 학습과 같은 인지 지능을 기계가 모방하는 것이라고 생각하면 됩니다. 물론 추론, 계획, 학습에만 국한되지는 않고, 보다 다양한 형태일 수 있습니다. [2]
이게 전부 데이터 사이언스랑 어떤 관련이 있습니까?
데이터 사이언스는 수학, 컴퓨터 과학, 도메인 지식 분야에서 도출된 기술과 이론을 사용하는, 학제를 넘나드는 분야입니다. [3] 데이터 과학이 무엇인지 설명하기 위해 저는 아래의 벤다이어그램을 사용하고 싶습니다.
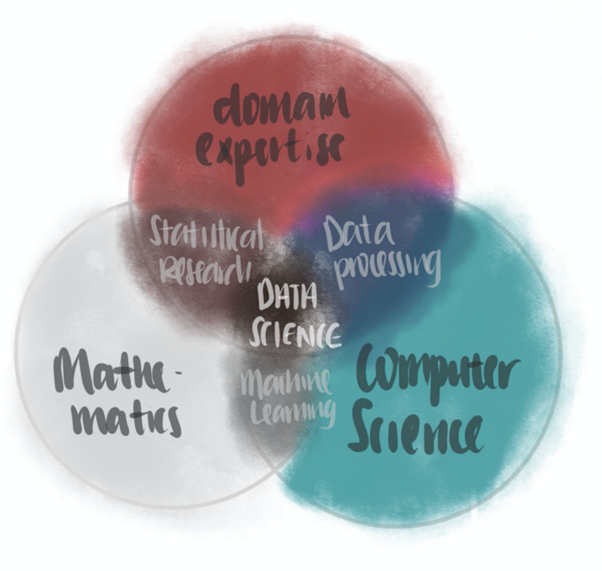
보시다시피 데이터 과학은 수학, 컴퓨터 과학 및 도메인 전문 지식과 같은 다양한 영역의 지식이 결합된 것입니다. 기계학습은 '수학'과 '컴퓨터 사이언스'를 만나는 지점에 있습니다. 대규모 데이터세트에 적용된 우아한 수학 방정식과 (컴퓨터의) 연산능력이 합류하는 지점인 것입니다. 따라서 머신러닝은 데이터 사이언스의 도드라진 구성 요소입니다.
다 알겠는데요, 어디서 배울 수 있나요?
우리가 학습할 수 있는 머신러닝 코스는 무수히 많습니다. 이것은 머신러닝 입문에서 대학원 수준 수업, 실제 수업에서 온라인 수업에 이르기까지 전방위적으로 제공되고 있습니다. 데이터 과학 분야의 초보자들에게 인기 있는 몇 가지 기계학습 입문 수업은 다음과 같습니다.
- Udacity의 기계 학습 수업 소개
- Python을 사용한 Datacamp의 / Dataquest 기계 학습 기초
- EdX 기반 Columbia University의 기계 학습
- Udemy의 기계 학습 A-Z
- Harvard University의 무료 기계 학습 과정
- ...
개인적으로 목록에 있는 이러한 기계학습 코스 중 일부를 시도해봤지만,
일부 수업은 깊이와 엄격함 측면에서 다소 부실했습니다.
데이터 과학자로서의 커리어 패스에 도움이 될 만한 엄격한 머신러닝 수업을 찾고 계시다면 이 포스팅이 분명 도움이 될 것 같습니다. 오늘 저는 개인적으로 가장 좋아하는 머신러닝 입문 강의를 공유하려 합니다. 바로 Coursera의 Andrew Ng(스탠포드 대학교)의 머신 러닝입니다. 필요한 선행 지식, 수업에서 뭘 얻을 수 있는지, 이 수업을 온전히 누릴 수 있는 방법에 대해 조언을 할까 합니다.
Coursera의 Andrew Ng의 머신 러닝
이 기계학습 과정은 초보자를 위한 최고의 기계학습 코스로 지속적으로 선전되어 왔습니다. 370만 명의 등록자가 내린150,000개 평가점수가 4.9점이라는 점도 이 코스가 얼마나 믿을 만한지 암시합니다.
무료로 수업에 참석할 수 있습니다(audit version). 학습자는 언제든지 무료로 등록할 수 있습니다. 단, 무료로 등록한 경우에는 수료증을 발급받을 수 없습니다. 대부분의 프로그래밍 연습과 퀴즈에 대한 피드백을 받을 수도 없습니다.
Coursera에서 7일 무료 평가판을 제공하고 있으며, 7일이 가기 전에 언제든지 과정을 반환할 수 있습니다.
인증서 비용은 $49입니다. 제 사견을 말씀드리면, 저는 이 수료증이 내가 수업을 완주하고자 하는 의지가 있음을 증명하는 훌륭한 방법이라 생각합니다. 도움이 필요한 학습자를 위한 재정적인 지원도 하고 있으므로 부담 가지지 마시고 Coursera에 문의해보십시오.
이 코스의 강사인 Andrew Ng는 소개가 거의 필요 없는 인물입니다. 그는 스탠포드 대학교 겸임교수이자 코세라(Coursera)와 구글 브레인(Google Brain)의 공동 설립자이자 바이두(Baidu)의 전 부사장으로, 머신러닝 분야에서 두말할 것 없이 가장 영향력 있는 인물입니다.

이 수업에서 특히 좋았던 점
1년 전 쯤에, 데이터 사이언스로 나아가고 싶지만 어디서부터 시작해야 할지 몰랐던 저는 '데이터 사이언스 배우는 방법'을 미친듯이 검색했습니다. 저는 엄청난 양의 배워야 할 것(수학, 확률, 통계, 기계학습 등)들과 그만큼 엄청난 양의 자원들에 빠르게 압도당했고, 가장 인기 있는 것처럼 보이는 수업을 듣게 되었습니다. 바로 Andrew Ng’s Machine Learning입니다.
지금의 저는 이 수업을 수강하게 된 것을 정말 기쁘게 생각합니다.
이 기계학습 과정을 마치고 데이터 사이언스 인턴십을 통해 행운을 시험해보려 했던 때가 생생하게 기억납니다. 정말 두려웠지만 수업을 들은 사실이 저를 조금 진정시켰습니다. 그 첫 번째 데이터 사이언스 직무 면접에서 제가 느낀 건, 대부분의 기계학습 실무자가 그 코스에 대해 알고 있거나, 익숙하다는 점입니다. 인터뷰 당시 제가 그 코스를 이수했다고 말했을 때 면접관이 수긍의 의미로 고개를 끄덕였는데 그게 기분 좋은 기억으로 남아있습니다.

내가 수업을 완료했다는 사실은 채용 관리자가 '수업에서 무엇을 배웠는가?', '수업에서 가장 어려웠던 부분?', '우리 회사의 상황에는 어떻게 적용할 수 있나?'와 같은 후속 질문을 할 수 있는 발판을 제공했습니다.
돌이켜 보면, 수업을 이수했다는 사실 자체가 학습동기의 표시이자 기계학습에 대한 기본 지식을 보유하고 있다는 신호로 인식되었을 수 있습니다. 두 가지 모두 고용 관리자가 데이터 사이언티스트를 고용하고자 할 때 보는 필수 자질입니다.
사실대로 이야기하자면, 이 코스만 있던 제 이력서로는 데이터 사이언트 인턴십에 채용될 수 없었습니다. 그러나 그 분야의 전문가들의 언어로 대화를 나눌 수 있다는 사실은 제게 큰 자신감을 주었습니다. 이를 통해 데이터 사이언스 전문가들과 네트워크를 구축하고 그들로부터 배울 수 있었습니다.
어떤 사람이 들으면 좋을까?
이 수업은 데이터 분석, 데이터 과학, 기계학습 또는 AI 분야에서 테크니컬한 역할을 추구하려는 진지한 학생을 대상으로 합니다. 또한 기계학습에 대한 배경 지식이 없는 초보자나 기계학습 개념을 복습하려는 사람들도 대상이 될 수 있습니다. 명시적으로 언급되지는 않았지만 이 수업은 수학적 엄격함을 요구합니다. 때문에 기계학습에 대한 깊은 이해를 원하는 학습자에게는 강한 배움의 자극이 되겠지만, 기계학습의 톱니바퀴에 관심이 거의 없는 학습자는 아마 떨어져나가게 될 겁니다.
쏟아야 할 시간은 만만치 않습니다. 수업을 이수하는 데에 약 60시간이 걸립니다. 매일 2시간을 투자할 수 있다고 가정하면 이 과정은 한 달이 걸립니다. 수학이나 프로그래밍 숙련도에 따라 이 소요시간이 다를 수는 있습니다.
이런 사람은 안 듣는 게 낫습니다.
그러니, 앞서 언급한 바를 염두에 둔다면 이 수업은 기계학습과 기계학습이 문제를 해결하는 방법에 대한 일반적인 질적 이해를 원하는 비기술적(non-technical) 학습자가 듣기엔 적절하지 않습니다. 만약 당신이 이런 사람이라면, Andrew Ng이 진행하는 AI for everyone을 수강하시는 게 더 나을 수 있습니다. 이 강의는 AI 전반과 전문 용어를 이해하고자 하는 비기술 전문가를 대상으로 합니다. 게다가 이 수업은 훨씬 더 짧아서 약 6시간만 투자하면 됩니다.
수학과 프로그래밍에 대한 개념이 없다면 이 과정 역시 쉽지는 않을 겁니다. 동기와 관심을 지속하는 것이 어렵다는 것을 이 강의를 통해 알게 될 수도 있습니다.
수학은 암만 해도 어렵습니다. 수학 없이 기계학습을 할 수는 없나요?
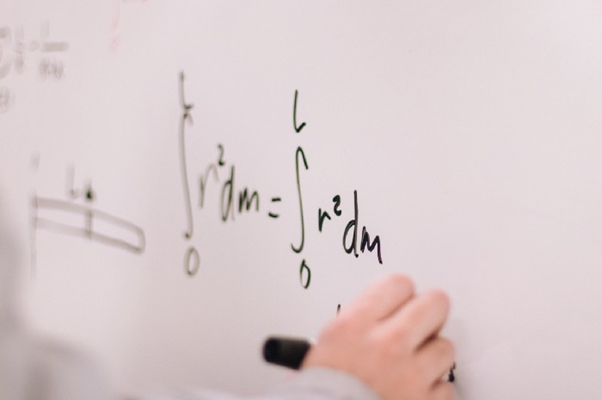
글쎄요, 수학을 이해하지 않고 기계학습을 수행할 때 치명적인 단점이 있습니다. 첫 번째, 기계학습을 맹목적으로 구현하는 기술(skill sets)을 당신이 가지고 있다면 당신은 Google Cloud에서 제공하는 것과 같은 자동화된 기계학습 AutoML에 의해 쉽게 대체할 수 있습니다. 두 번째, 데이터 과학자의 가치는 런타임 및 저장 복잡성과 데이터세트에 대한 적합성까지 고려하여 최상의 성능을 발휘하는 적절한 알고리즘을 신중하게 선택하는 데 있습니다.
당신이 자동차의 소유자라고 상상해보십시오. 물론 차가 달릴 때 부드럽게 운전할 수 있습니다. 그러나 자동차를 만들어야 하거나 자동차 결함을 해결해야 하는 경우에는, 자동차를 달리게 하는 톱니바퀴와 바퀴에 대한 이해가 필요합니다. 자동차의 내부 작동을 이해하지 못한다면 이들 중 어느 것도 불가능합니다. 이 자동차는 데이터 사이언스의 알고리즘입니다. 내부에서 어떻게 작동하는지 모른다면 기계학습 알고리즘을 구축할 수 없습니다.
데이터 사이언티스트, 분석가 및 엔지니어로서 우리의 역할은 기계학습 모델을 사용하는 것뿐만 아니라 이를 구축, 유지 관리 및 배포하는 것입니다. 그러려면 수학을 알아야 합니다.
알겠습니다. 배우고 싶은데, 수학이나 코딩에 대한 배경지식이 없습니다...
걱정 마세요! Coursera에는 수업에 대한 전제 조건이 없습니다. 아래에 제가 언급할 강의를 듣지 않고도 코스를 시작할 수 있습니다. 그러나 코스를 성공적으로 마치고자 한다면 몇 가지는 선행학습 하시는 게 좋습니다.
권장하는 코딩 지식
Datacamp 및 Dataquest의 python 및 R 과정에 참석한 저는 MATLAB 및 python에 대한 기본적인 이해를 바탕으로 이 과정을 시작했습니다. 이 과정은 초반부터 MATLAB에 대한 간략하고 쉬운 소개를 제공하므로, 코딩 경험이 없어도 걱정 안 해도 됩니다. 이는 학습자가 필요한 코딩 능력을 빠르게 익히는 데 도움이 됩니다.
만약 다른 프로그래밍 언어에는 익숙하지만 MATLAB에는 익숙하지 않은 경우에는 해당 언어에 대해 너무 신경쓰지 말고 바로 과정을 시작하는 것이 좋습니다. 그러나 여전히 MATLAB을 배우는 데 시간을 할애하고 싶다면 다음과 같은 훌륭한 자원들이 있습니다.

권장하는 수학 코딩 지식
제가 추천한 코세라 강의는 고등학교 수준의 미적분 및 선형 대수학에 대한 약간의 지식을 전제합니다. 수학에 능숙할수록 코스를 쉽게 통과할 수 있으며 그 반대의 경우도 마찬가지입니다.
Andrew Ng의 수업은 선형 대수학에서 약간의 복습을 제공하므로 선형 대수학 지식이 가물가물하더라도 걱정할 필요 없습니다. 하지만 수업을 시작하기 전에 다음 질문을 스스로에게 하는 것이 좋습니다.
- 차별화 규칙을 자신 있게 알고 있습니까? 그렇지 않다면 Khan Academy의 미적분 수업을 찾아보세요.
- 행렬이 무엇이며 행렬에 대한 연산(전치, 산술, 내적)을 수행하는 방법을 알고 있습니까? 그렇지 않다면 Khan Academy’s Linear Algebra playlist를 찾아보세요.
다음 그림은 수업에서 마주한 몇 가지 수학 문제입니다. 이런 표기법이 편안하세요? 그렇지 않다면 위의 링크로 들어가서 얼른 지식을 환기해두시는 게 좋습니다.
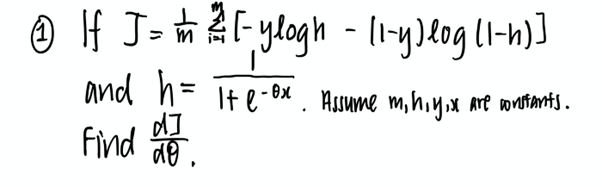
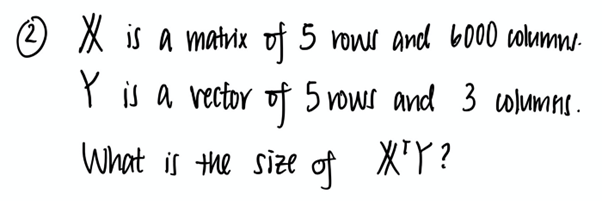
뭘 배워갈까?
기계학습을 배우려면 일반적으로 알아야 할 사항
- 기계학습으로 해결할 수 있는 다양한 유형의 문제.
- 다양한 문제를 해결하기 위한 다양한 유형의 알고리즘.
- 서로 다른 데이터세트에 대한 각 알고리즘의 강점과 약점.
- 각 알고리즘을 뒷받침하는 수학 및 가정.
- 기계학습의 절충trade-off(편향-분산 절충)
- 기계학습의 모범 사례.
- 기계학습 알고리즘의 적용.
이러한 개념을 다루기 위해 Andrew Ng의 수업은 알고리즘별로 구성된 장으로 나뉩니다. 각 클래스는 논리적으로 진행됩니다. 먼저 알고리즘에 대한 간략한 소개와 실제 적용 사례를 제공하여 독자를 준비시킵니다. 그런 다음 설득력 있는 다이어그램 설명을 통해 알고리즘에 대한 독자의 직관을 구축합니다. 이러한 직관은 알고리즘의 수학을 이해하는 마찰을 줄여줍니다.
강의 후에는 퀴즈를 통해 이해도를 테스트할 수 있습니다. 학습내용을 내재화하기 위해 첫 번째 원칙을 사용하여 Matlab에서 알고리즘을 처음부터 구현할 수도 있습니다.

이 수업에서 배우게 될 내용
이 과정은 기계학습 분야의 핵심에 대한 폭넓은 조감도를 제공합니다. 다음은 수업에서 다루는 개념의 마인드맵입니다.

함께 보면 좋을 책
Andrew Ng의 코스에는 공식 교과서가 없지만 확신이 서지 않을 때 교과서를 참조하는 게 도움이 됩니다. 이를 위해 저는 무료로 온라인 제공되는 교재인 Introduction to Statistical Learning(온라인 Free)을 추천합니다. 이 책은 머신러닝 알고리즘에 대한 수학적 직관력을 높일 수 있도록 명쾌한 설명과 삽화를 제공합니다. 한 가지 주의할 점은 R을 기본 언어로 사용한다는 것입니다.
발전을 위한 팁과 요령
- 질문
같은 자리에 오래 머무르는 것은 정말 쉽습니다. Coursera는 당신과 같은 학습자가 질문할 수 있는 포럼을 제공합니다. 도움을 줄 사람이 필요하면 언제든지 저에게도 개인적으로 연락하십시오. 제가 할 수 있는 한 최대한 도와 드리겠습니다.
- 천천히 흡수
이 코스에서 다루는 개념은 결코 간단하지 않습니다. 수업을 소화하며 진행하는 것은 지극히 바람직한 일이므로 천천히 수강하십시오.
- 약간의 휴식을 취하십시오.
특정 코드 블록을 끈덕지게 시도했지만 원하는 출력을 제공하지 않으면 한 걸음 물러나서 휴식을 취해야 할 때일 수 있습니다.
- 도중에 메모를 합니다.
종이에 메모하고 코딩하는 것이 다이어그램을 그려 개념을 시각화하는 것만큼 유용하다는 것을 알았습니다. 또한 내 생각을 공식화하는 데 도움이 되기 때문에 내 컴퓨터에 코드를 구현하기 전에 종이에 코드를 적어두는 것이 도움이 됩니다.

확신이 든다면 오늘 시도해 보시기 바랍니다.
이 코스 후에는,
축하합니다! 이제 코스를 하나 수료하고 당신은 지식에 굶주린 사람이니 기계학습이 무엇이고, 수학적 기초가 무엇인지에 대한 더 많은 지식을 얻을 준비가 된 것입니다. 다음은 당신에게 드리는 몇 가지 제안입니다.
- Other data science skills(SQL, python 및 R)에 대한 복습
- 새로 발견한 기술을 시험해볼 흥미로운 프로젝트
- 통계 및 확률 수업
- Coursera의 deep learning 수업
- 이 코스의 고급 버전인, CS229 Machine Learning 수강(이를 위해서는 선형 대수학, 통계 및 확률에 대한 고급(학부/대학원) 이해가 필요)
머신러닝을 전혀 몰랐던 학습자로서 이 강의를 듣고 나니 엄청난 희망이 생겼습니다. 다른 기계학습 및 데이터 사이언스의 개념을 배울 수 있는 훌륭한 토대를 제공해 주었습니다. 꾸준히 하시면 단시간에 코스를 마치고 저와 같은 성취감을 받으실 수 있으실 거라 확신합니다.
참고문헌
[1] Mitchell, Tom (1997). Machine Learning. New York: McGraw Hill. ISBN 0–07–042807–7. OCLC 36417892.
[2] Russell, Stuart J.; Norvig, Peter (2009). Artificial Intelligence: A Modern Approach (3rd ed.). Upper Saddle River, New Jersey: Prentice Hall. ISBN 978–0–13–604259–4.
[3] Dhar, V. (2013). “Data science and prediction”. Communications of the ACM. 56 (12): 64–73. doi:10.1145/2500499. S2CID 6107147. Archived from the original on 9 November 2014. Retrieved 2 September 2015.
'Programming > Knowledge' 카테고리의 다른 글
| [웹개발] 파이썬 웹 프레임워크(Web Frameworks)에 대한 간단 지식과 추천 프레임워크 (0) | 2022.01.15 |
|---|---|
| [머신러닝 for 비즈니스] 비즈니스에 가치를 더하는 기계학습 인프라 구축 6단계 (0) | 2021.09.10 |
| [데이터사이언티스트 독학 04] 취업하고자 한다면 데이터 사이언스 프로젝트를 수행하라 (0) | 2021.08.26 |
| [데이터 사이언티스트 독학 02] 데이터 과학에 필요한 수학, 확률과 통계 배우기 (0) | 2021.08.19 |
| [데이터 사이언티스트 독학 01] Data Science의 정의, 데이터 처리(Data Processing)를 배우는 방법 (0) | 2021.08.18 |




댓글