싱가폴 출신의 데이터 사이언티스트, Travis Tang님의 아티클을 번역한 글입니다.
데이터 사이언티스트 wannabe라면, 일독할 가치가 충분한 글입니다.
Travis Tang님은 화학공학을 전공했지만 테크기업에서 데이터 분석가로 사회생활을 시작했습니다.
몇 차례에 걸쳐 포스팅 될 그의 이 아티클은 화학공학도가
데이터 사이언티스트로 일하기까지의 여정과 필요한 스킬셋(skill set)을 구체적으로 담고 있습니다.
Tang은, 데이터 사이언티스트로 나아가는 데 필요한 정보는 홍수처럼 넘치는데
오히려 그 때문에 최고의 자원을 선별해내는 것이 어렵다고 토로합니다.그렇기 때문에 먼저 아래의 질문에 답을 할 수 있어야 한다고 강변합니다.

데이터 과학이란 무엇입니까?
아, 이것은 인사 담당자와 기업의 면접관 모두를 당황하게 만드는 대답하기 어려운 질문입니다. 사실, 회사마다 데이터 과학을 다르게 정의하여 용어가 모호하고 다소 이해하기 어렵습니다. 프로그래밍이라고 하는 사람도 있고 수학이라고 말하는 사람도 있고 데이터를 이해하는 일이라고 말하는 사람도 있습니다. 모두 어느 정도 맞는 말입니다. 나(Travis Tang)에게 가장 동의하는 정의는 다음과 같습니다.
데이터 사이언스data science는 수학, 컴퓨터 과학, 도메인 지식 분야에서 도출된 기술과 이론을 사용하는, 학제를 넘나드는(inter-disciplinary) 분야이다.
아래 그림은 위의 정의를 잘 보여주는 이미지입니다.

이 이미지에서 각 분야의 지식이 뭉쳐 데이터 과학을 형성한다는 것을 보여주기 위하여 분야 사이의 경계를 흐릿하게 묘사했습니다.
자, 그럼 데이터 사이언스, 데이터 과학을 배우기 위해선 뭘 해야 할까요?
일련의 게시물을 통해 저는 데이터 사이언티스트로 나아가는 과정에서 제가 배운 것들을 알려드리려 합니다. 이를 통해 저와 같은 입장에 있는 분들이 데이터 사이언스를 배워나가는 데에 도움이 되었으면 합니다. 이 아티클은 아래와 같은 내용으로 구성될 예정입니다.
1부 — SQL, Python 및 R을 사용한 데이터 처리(본 게시물의 내용)
2부 — 수학, 확률 및 통계
3부 — 컴퓨터 과학 기초
4부 — 기계학습(머신러닝)
5부 — 첫 번째 기계 학습 프로젝트 구축
첫 번째 게시물인 이 글에서는 데이터 사이언티스트에게 필요한 데이터 처리(data processing) 지식에 대해 주로 다루게 될 것입니다. 제가 생각할 때 데이터를 처리와 관련해서는 일반적으로 아래의 것들을 배워야 합니다.
- SQL(Standard Query Language)을 사용하여 데이터베이스에서 데이터를 추출하고
- 데이터 정리/ 조작/ 분석(일반적으로 Python 및/또는 R 사용)하여,
- 데이터를 효과적으로 시각화합니다.
SQL을 이용한 데이터 추출
SQL은 데이터가 있는 데이터베이스와 통신하는 언어입니다. 데이터가 지하에 묻혀 있는 보물이라면 SQL은 보물의 원시 형태를 파헤치는 삽입니다. 보다 구체적으로 말하면, SQL을 사용해 데이터베이스에 있는 하나 또는 여러 테이블의 조합에서 정보를 추출할 수 있습니다.

SQL Server, PostgreSQL, Oracle, MySQL 및 SQLite와 같이 SQL에는 다양한 선택지가 있습니다. 이들 각각은 조금씩 다르지만 구문(문법)은 대체로 유사하므로 굳이 이들 중 하나를 선택하는 데에 긴 시간을 보낼 필욘 없습니다.
언어를 배우려면 먼저 단어를 학습한 다음 문장으로 결합하고 단락을 구성해야 합니다. SQL 역시 마찬가지입니다.
아주 기본적인 개념(SQL의 단어나 문장)을 배우기 위해 Datacamp(Introduction to SQL)와 Dataquest(SQL Fundamentals)라는 플랫폼을 활용했습니다. (나중에 Datacamp와 Dataquest의 장단점에 대해 설명하겠습니다.) 일반적으로 이러한 사이트는 연습과 예제를 통해 필수 SQL 기술을 경험할 수 있습니다. 이 단계에서 기억해야 할 몇 가지 개념은 다음과 같습니다.
- 필터링 및 선택을 위한 SELECT 및 WHERE
- 데이터 집계를 위한 COUNT, SUM, MAX, GROUP BY, HAVING
- 유용한 고유 목록 및 고유 집계를 생성하기 위한 DISTINCT, COUNT DISTINCT
- OUTER JOIN(예: LEFT) 및 INNER JOIN을 언제/어디서 사용할지
- 문자열 및 시간 변환
- UNION 및 UNION ALL.
(잘 알지 못 해도 상관 없습니다! 배우면 되니까요.)
사실 이것들을 숙지한다고 해서 분석가로서 충분히 준비된 상태라 볼 수는 없습니다. 단어와 문장을 이해할 수는 있지만 전체 문단을 쓰기에는 추가적인 스킬이 필요할 겁니다. 특히, 하위 쿼리(sub-query) 및 창(window) 기능과 같은 일부 중/고급 개념은 구직면접에서 테스트 항목으로도 출제되는 편이며, 분석가로서 역할을 수행하기 위해서도 반드시 필요합니다. 이러한 기술에는 다음이 포함됩니다.
- COALESCE로 NULL 처리
- 하위 쿼리와 쿼리 효율성에 미치는 영향
- 임시 테이블
- 자체 조인
- PARTITION, LEAD, LAG와 같은 창 기능
- 사용자 정의(UDF) 기능
- 작업을 더 빠르게 하기 위해 쿼리에 인덱스를 사용
이러한 기술을 배우기 위해 저는 주로 무료이며 각 개념에 대해 매우 어려운 예제를 제공하는 SQLZoo.net을 주로 사용하였습니다. SQLZoo에서 가장 좋아하는 기능은 하나의 통합 문제에서 다양한 개념을 테스트하는 연습문제가 있다는 것입니다. 예를 들어 다음과 같은 엔터티-관계 다이어그램이 제공되고 이를 기반으로 복잡한 쿼리를 생성하도록 요구합니다.
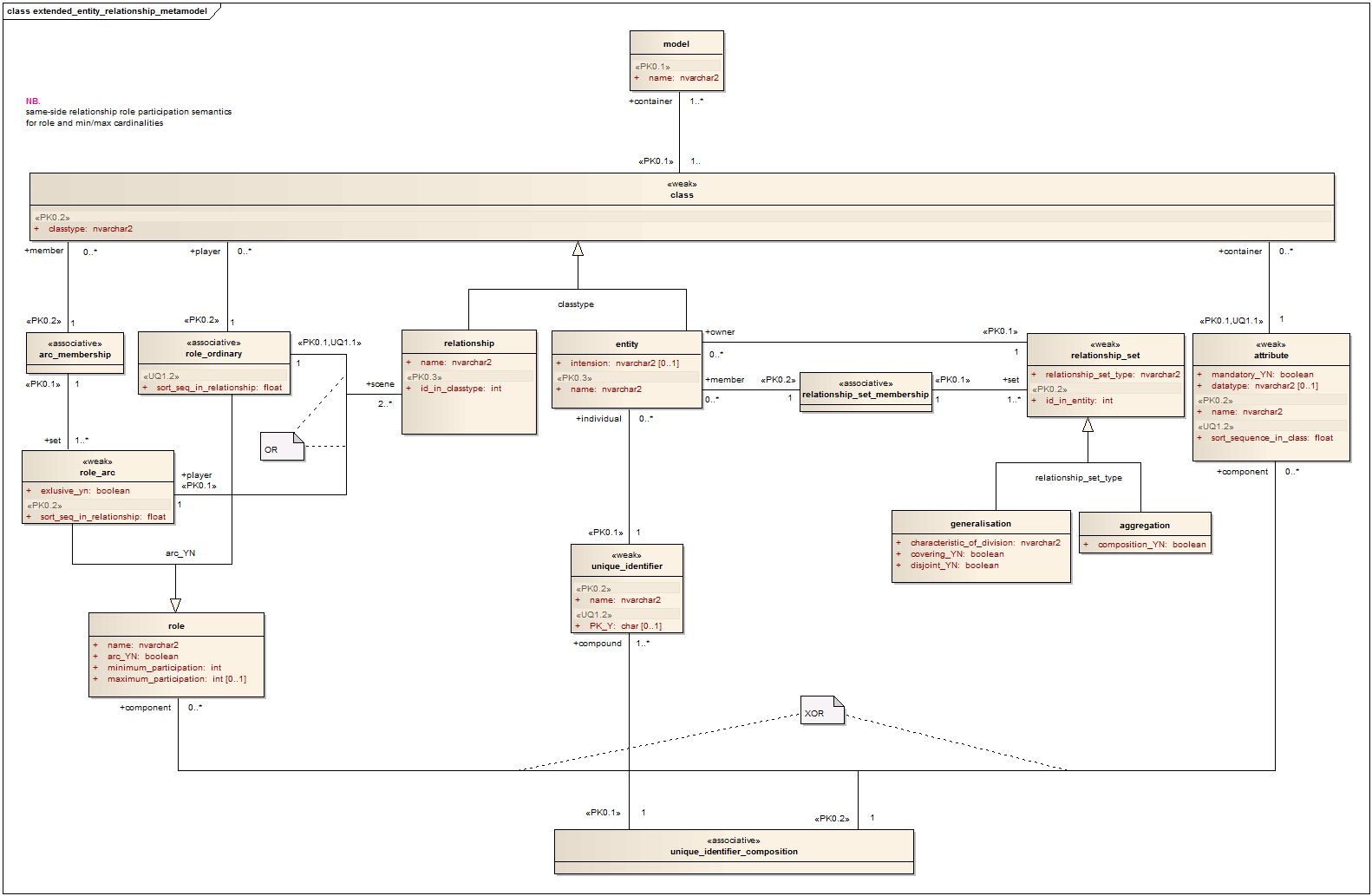
이 과업들은 전문 분석가(analyst)가 하는 일에 가깝습니다. 분석가는 동일한 데이터베이스로부터 정보를 추출하기 위해 다양한 기술들을 배워 사용합니다. 여기 SQLZoo의 예제 링크를 걸어두었습니다. 'Help Desk'의 엔터티-관계 다이어그램입니다. 주어진 상황에서 당신은 2017년 08월 12일 하루 중 각 시간에 수신된 전화 수와 관리자를 표시해야 합니다. (여기서 직접 해보세요!)
제가 활용한 다른 리소스로는 Zachary Thomas의 SQL 예제 및 Leetcode가 있습니다.
R과 Python을 사용해 데이터 다루기(manipulation)
데이터 과학에 필요한 프로그래밍과 도구에 대해 배우려면 R이나 Python에서 벗어날 수 없습니다. 이 둘은 데이터 조작, 시각화를 비롯, 데이터를 지지고 볶는 데에 사용되는 매우 인기 있는 프로그래밍 언어입니다. R이 우월한가 Python이 우월한가는 그 자체로 별도의 포스팅을 할 가치가 있는 질문입니다. 제 의견은요,
R을 선택하든 파이썬을 선택하든 상관없습니다. 하나를 마스터하면 다른 하나는 쉽게 익힐 수 있습니다.
Python 및 R로 코딩하는 여정은 CodeAcademy, Datacamp, Dataquest, SoloLearn 및 Udemy와 같은 코드 사이트에서 시작되었습니다. 이 사이트는 언어 또는 패키지별로 구성된 자습형 수업을 제공합니다. 이들 플랫폼은 먼저 개념을 설명해주고, 사용자에게 공백을 제시하며 코드로 채울 것을 요구합니다. 이러한 사이트는 일반적으로 간단한 데모를 통해 방금 배운 개념을 즉시 연습할 수 있습니다. 일부는 나중에 프로젝트 기반 예제를 제공합니다.
오늘은 저는 제가 가장 좋아하는 두 가지인 Datacamp와 Dataquest를 집중적으로 다루겠습니다.
Datacamp데이터캠프
DataCamp는 현장 전문가의 비디오 강의와 빈칸 채우기 연습을 제공합니다. 비디오 강의는 대부분 간결하고 효율적입니다.
DataCamp에서 내가 좋아하는 부분 중 하나는 SQL, R 및 python 관련 커리어 패쓰별로 구성된 과정입니다. 이를 통해 커리큘럼 을 직접 고민해야 하는 수고를 덜 수 있습니다. 이제 관심 있는 경로를 따라가면 됩니다. 다음과 같은 경로가 제공됩니다.
- Python/R의 데이터 사이언티스트
- Python/R/SQL의 데이터 분석가
- Python/R의 기계학습(머신러닝) 전문가
- 파이썬/R 프로그래머
개인적으로 저는 "R의 데이터 사이언티스트로 R 교육을 시작했습니다. 이 교육에서는 데이터를 구성, 조작 및 시각화하는 데 매우 유용한 데이터 패키지의 모음인 R의 Tidyverse에 대해 상세하게 소개합니다. ggplot2(데이터 시각화용), dplyr(데이터 조작용) 및 stringr(텍스트 분석용)이 포함되어 있습니다.
그러나 DataCamp에 대한 불만도 있습니다. DataCamp를 완료한 후에는 머릿 속에 지식이 제대로 남지 않는다는 점입니다. 빈칸 채우기 형식을 사용하는지라, 개념을 제대로 이해하지 않고도 빈칸에 무엇이 필요한지 쉽게 추측할 수 있기 때문입니다. 제가 이 플랫폼을 통해 배우던 때에 가능한 한 짧은 시간에 최대한 많은 과정을 완료하려는 욕심이 있었습니다. 그러다보니 코드를 훑어보고 더 큰 그림을 이해하지 못한 채 빈칸 채우기에만 급급했습니다. DataCamp에 대한 학습을 다시 시작할 수 있다면, 코드 전체를 더 잘 소화하고 이해하기 위하여 시간을 더 할애할 것입니다.
Dataquest데이터퀘스트
Dataquest는 DataCamp와 매우 유사합니다. 프로그래밍 개념을 설명하기 위해 코드에 따른 연습을 사용하는 데 중점을 둡니다. Datacamp와 마찬가지로 R, Python 및 SQL로 다양한 과정을 제공하지만 DataCamp보다는 확장성이 떨어집니다. 예를 들어 Datacamp와 달리 Dataquest는 비디오 강의를 제공하지 않습니다.
Dataquest에서 제공하는 일부 트랙은 다음과 같습니다.
- R/Python의 데이터 분석가
- 파이썬의 데이터 과학
- 데이터 엔지니어링
DataQuest의 콘텐츠는 일반적으로 DataCamp의 콘텐츠보다 어렵습니다. 빈칸 채우기 형식에 따른 지식 보존 문제도 적습니다. 시간이 더 걸리긴 했지만 DataQuest를 통해 익힌 지식은 머릿속에 더 오래 남았습니다.
DataQuest의 또 다른 훌륭한 기능은 이력서를 검토하고 기술 지침을 제공할 멘토와 월마다 통화할 수 있다는 점입니다. 멘토와 개인적으로 연락하지는 않았지만 훨씬 더 빨리 발전하는 데에는 확실히 도움이 되었을 것이라 생각합니다.
데이터 시각화
데이터 시각화는 데이터에서 도출한 통찰력을 제시(present)하는 핵심입니다. Python과 R을 사용하여 차트를 만드는 기술을 배운 후 Cole Knaflic의 <Storytelling with Data>(역자주: 국내에서는 '데이터 스토리텔링'이라는 제목으로 번역본이 판매되고 있는데 그야말로 끔찍한 번역)라는 책에서 데이터 시각화의 원리를 배웠습니다.
이 책은 툴에 의존하지 않습니다. 즉, 특정 소프트웨어에 초점을 맞추지 않고 통찰력 있는 예시를 통해 데이터 시각화의 일반적인 원리를 가르칩니다. 이 책에서 기대할 수 있는 몇 가지 핵심 사항은 다음과 같습니다.
- 컨텍스트 이해
- 효과적인 시각 자료 선택
- 어수선함 제거
- 원하는 곳에 주목
- 디자이너처럼 생각하라
- 이야기를하다
나는 이 책을 읽기 전까지 데이터 시각화를 안다고 생각했습니다.
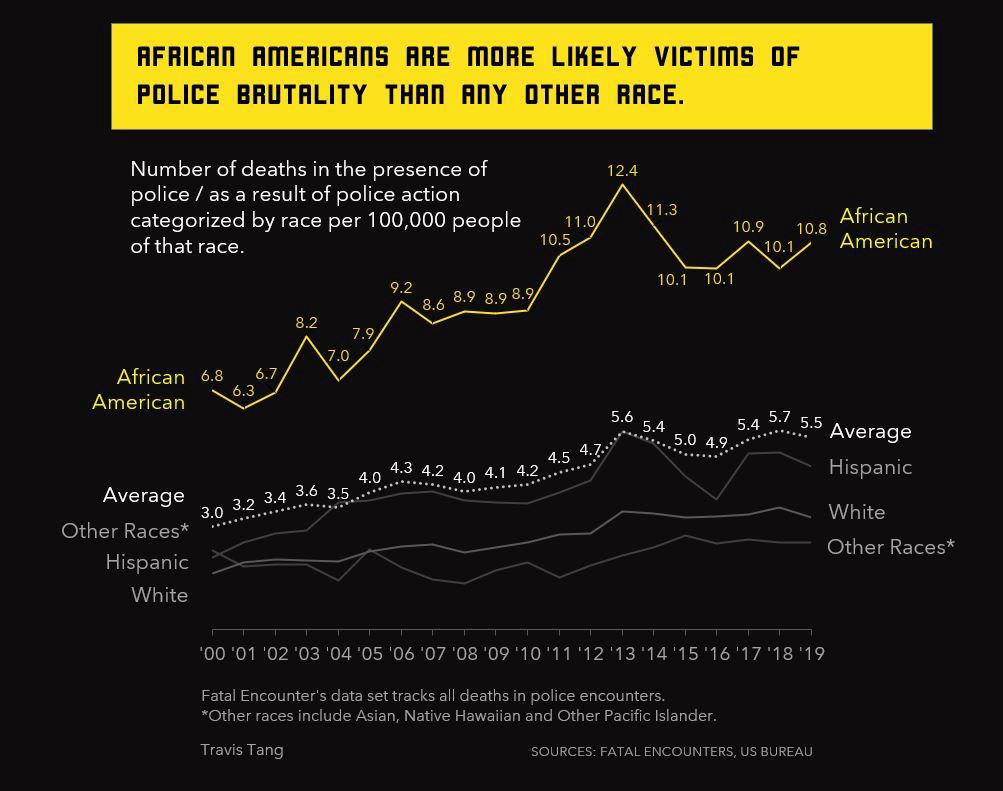
책을 소화한 후, 나는 흑인에 대한 경찰의 만행을 설명하는 (다소) 시각적으로 즐거운 차트를 만들 수 있었습니다. 여기에 적용된 책의 주요 학습 포인트 중 하나는 원하는 곳에 주의를 집중시키는 것이었습니다. 이것은 BLM 색상을 연상시키는 밝은 노란색으로 아프리카 계 미국인 라인을 강조 표시함으로써 달성되었으며, 나머지 차트는 흰색 및 회색과 같은 더 흐릿한 음영으로 배경에 머물도록 조치했습니다.
그 외 읽을거리
이 블로그 게시물에 마음에 들었다면 기계학습에 대한 다른 아티클도 읽어보세요.
- How to be a Data Analyst — Data Viz with Google Data Studio
- What makes great wine… great? (Using Machine Learning and Partial Dependence Plot in the quest for a good wine)
- Interpreting Black-Box ML Models using LIME (Understand LIME Visually by Modelling Breast Cancer Data)
참고문헌
[1] Dhar, V. (2013). “Data science and prediction”. Communications of the ACM. 56 (12): 64–73. doi:10.1145/2500499. S2CID 6107147. Archived from the original on 9 November 2014. Retrieved 2 September 2015.
다음 포스팅에서는
이 게시물에서는 제가 프로그래밍을 배우면서 출발점으로 삼은 스킬셋에 대해 다루었습니다. 이 과정을 통해 이제 데이터를 조작하는 데 필요한 기술을 갖추게 되었습니다! 하지만 아직 갈 길이 꽤 멉니다. 남은 스킬들에 대해서는 다음 포스팅에서 다루겠습니다
2부 — 수학, 확률 및 통계
3부 — 컴퓨터 과학 기초
4부 — 기계학습(머신러닝)
5부 — 첫 번째 기계학습(머신러닝) 프로젝트 구축
'Programming > Knowledge' 카테고리의 다른 글
| [웹개발] 파이썬 웹 프레임워크(Web Frameworks)에 대한 간단 지식과 추천 프레임워크 (0) | 2022.01.15 |
|---|---|
| [머신러닝 for 비즈니스] 비즈니스에 가치를 더하는 기계학습 인프라 구축 6단계 (0) | 2021.09.10 |
| [데이터사이언티스트 독학 04] 취업하고자 한다면 데이터 사이언스 프로젝트를 수행하라 (0) | 2021.08.26 |
| [데이터 사이언티스트 독학 03] 기계학습(머신러닝)은 무엇인가, 어디서 배울 수 있나 (0) | 2021.08.21 |
| [데이터 사이언티스트 독학 02] 데이터 과학에 필요한 수학, 확률과 통계 배우기 (0) | 2021.08.19 |




댓글